背景
PolarDB PostgreSQL(以下簡稱PolarDB)是一款阿里雲自主研發的企業級資料庫產品,採用計算儲存分離架構,相容PostgreSQL與Oracle。PolarDB 的儲存與計算能力均可橫向擴充套件,具有高可靠、高可用、彈性擴充套件等企業級資料庫特性。同時,PolarDB 具有大規模平行計算能力,可以應對OLTP與OLAP混合負載;還具有時空、向量、搜尋、圖譜等多模創新特性,可以滿足企業對資料處理日新月異的新需求。
PolarDB 支援多種部署形態:儲存計算分離部署、X-Paxos三節點部署、本地盤部署。
傳統資料庫的問題
隨著使用者業務資料量越來越大,業務越來越複雜,傳統資料庫系統面臨巨大挑戰,如:
- 儲存空間無法超過單機上限。
- 通過只讀例項進行讀擴充套件,每個只讀例項獨享一份儲存,成本增加。
- 隨著資料量增加,建立只讀例項的耗時增加。
- 主備延遲高。
PolarDB雲原生資料庫的優勢
針對上述傳統資料庫的問題,阿里雲研發了PolarDB雲原生資料庫。採用了自主研發的計算叢集和儲存叢集分離的架構。具備如下優勢:
- 擴充套件性:儲存計算分離,極致彈性。
- 成本:共享一份資料,儲存成本低。
- 易用性:一寫多讀,透明讀寫分離。
- 可靠性:三副本、秒級備份。
PolarDB整體架構簡介
下面會從兩個方面來解讀PolarDB的架構,分別是:儲存計算分離架構、HTAP架構。
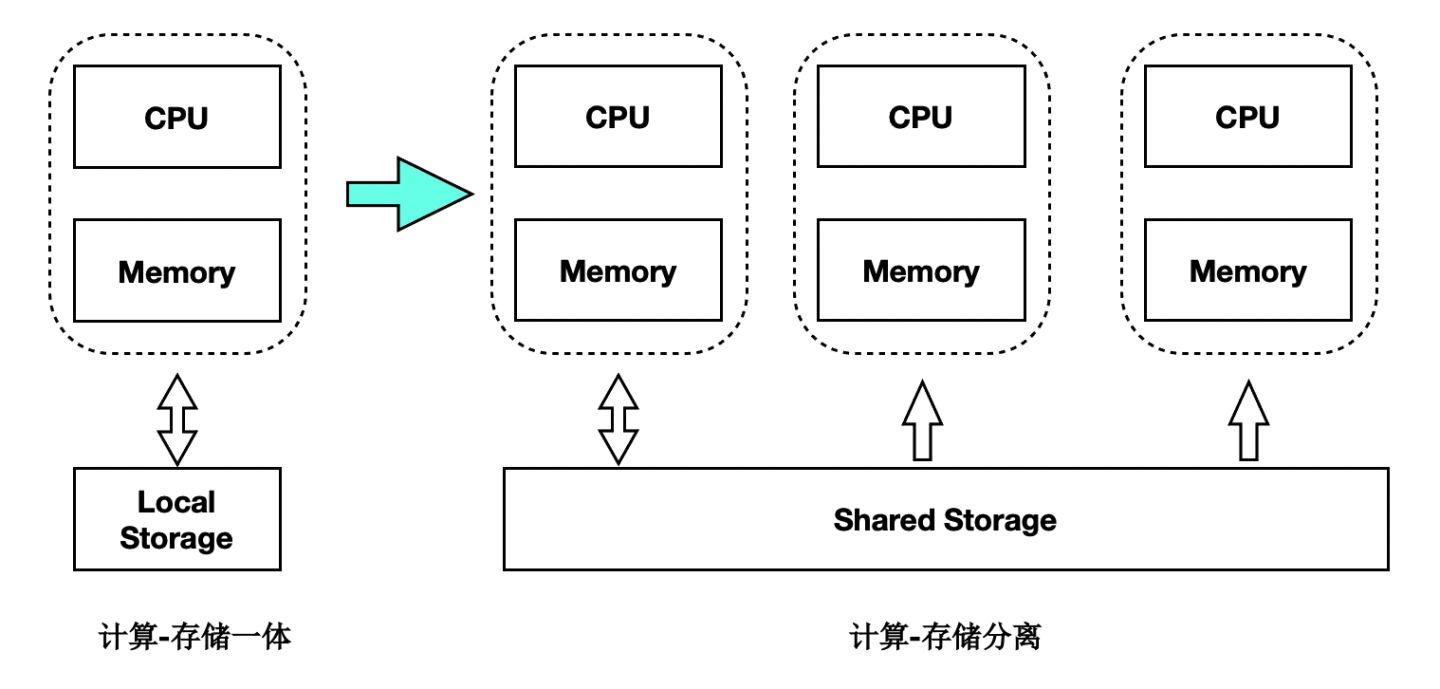
儲存計算分離架構
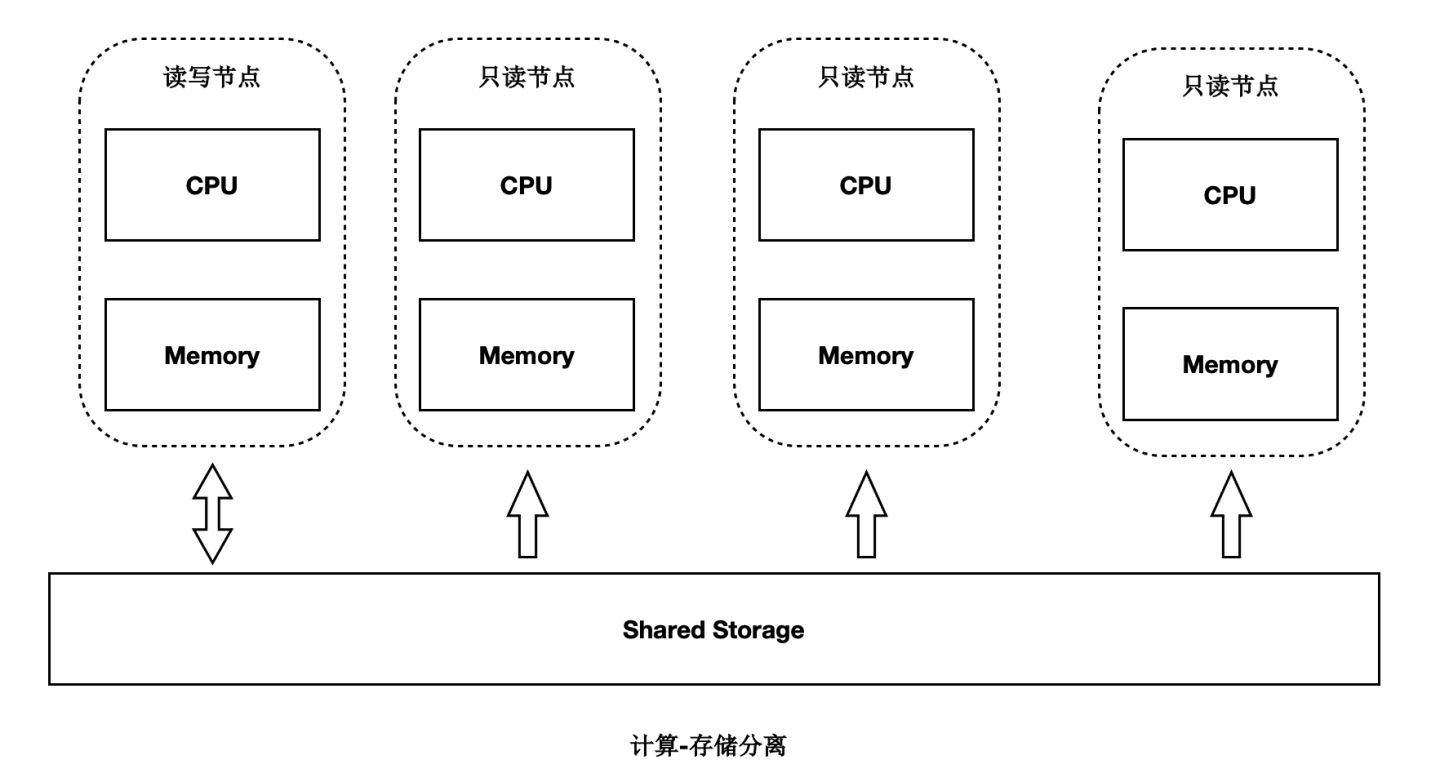
PolarDB是儲存計算分離的設計,儲存叢集和計算叢集可以分別獨立擴充套件:
- 當計算能力不夠時,可以單獨擴充套件計算叢集。
- 當儲存容量不夠時,可以單獨擴充套件儲存叢集。
基於Shared-Storage後,主節點和多個只讀節點共享一份儲存資料,主節點刷髒不能再像傳統的刷髒方式了,否則:
- 只讀節點去儲存中讀取的頁面,可能是比較老的版本,不符合他自己的狀態。
- 只讀節點指讀取到的頁面比自身記憶體中想要的資料要超前。
- 主節點切換到只讀節點時,只讀節點接管資料更新時,儲存中的頁面可能是舊的,需要讀取日誌重新對髒頁的恢復。
對於第一個問題,我們需要有頁面多版本能力;對於第二個問題,我們需要主庫控制髒頁的刷髒速度。
HTAP架構
讀寫分離後,單個計算節點無法發揮出儲存側大IO頻寬的優勢,也無法通過增加計算資源來加速大的查詢。我們研發了基於Shared-Storage的MPP分散式並行執行,來加速在OLTP場景下OLAP查詢。 PolarDB支援一套OLTP場景型的資料在如下兩種計算引擎下使用:
- 單機執行引擎:處理高併發的OLTP型負載。
- 分散式執行引擎:處理大查詢的OLAP型負載。
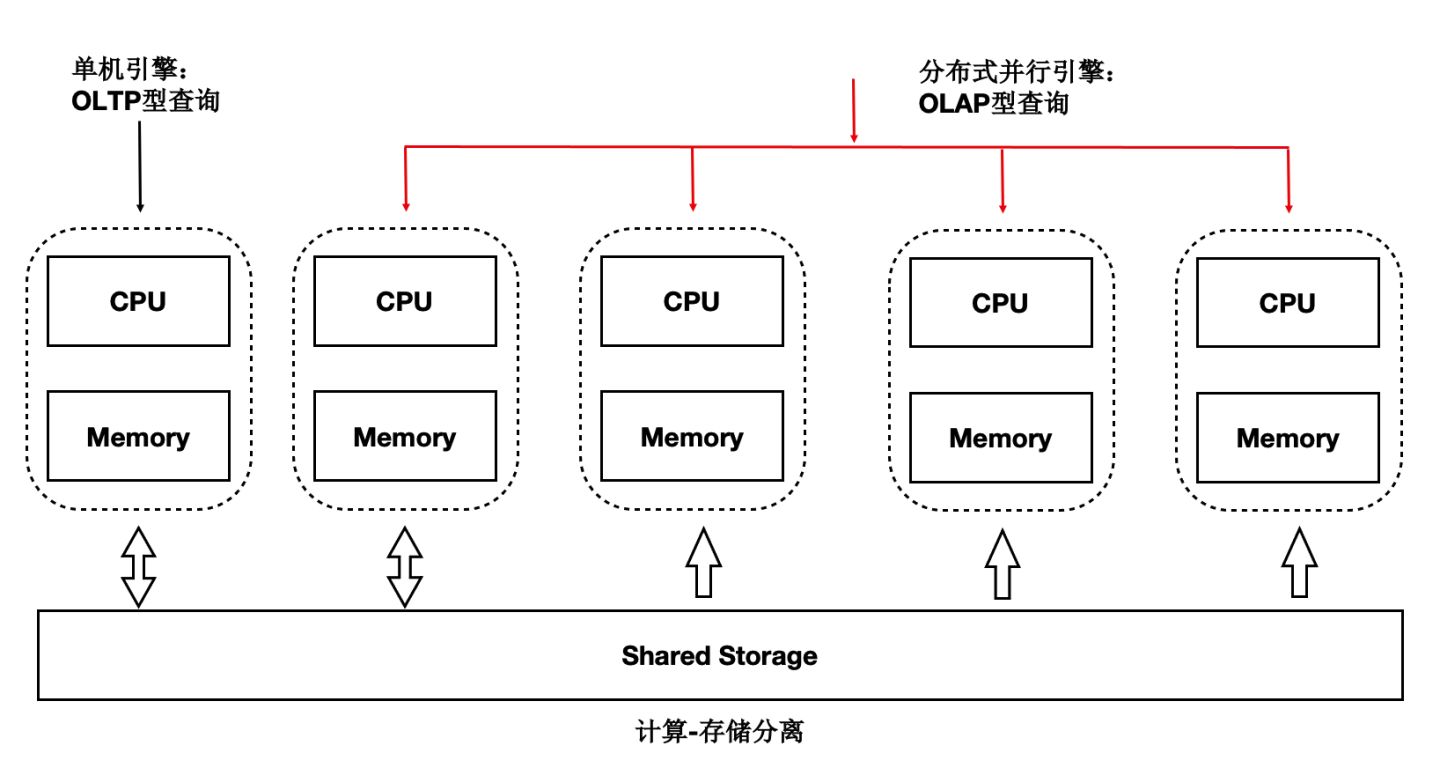
在使用相同的硬體資源時效能達到了傳統Greenplum的90%,同時具備了SQL級別的彈性:在計算能力不足時,可隨時增加參與OLAP分析查詢的CPU,而資料無需重分佈。
PolarDB - 儲存計算分離架構
Shared-Storage帶來的挑戰
基於Shared-Storage之後,資料庫由傳統的share nothing,轉變成了shared storage架構。需要解決如下問題:
- 資料一致性:由原來的N份計算+N份儲存,轉變成了N份計算+1份儲存。
- 讀寫分離:如何基於新架構做到低延遲的複製。
- 高可用:如何Recovery和Failover。
- IO模型:如何從Buffer-IO向Direct-IO優化。
架構原理
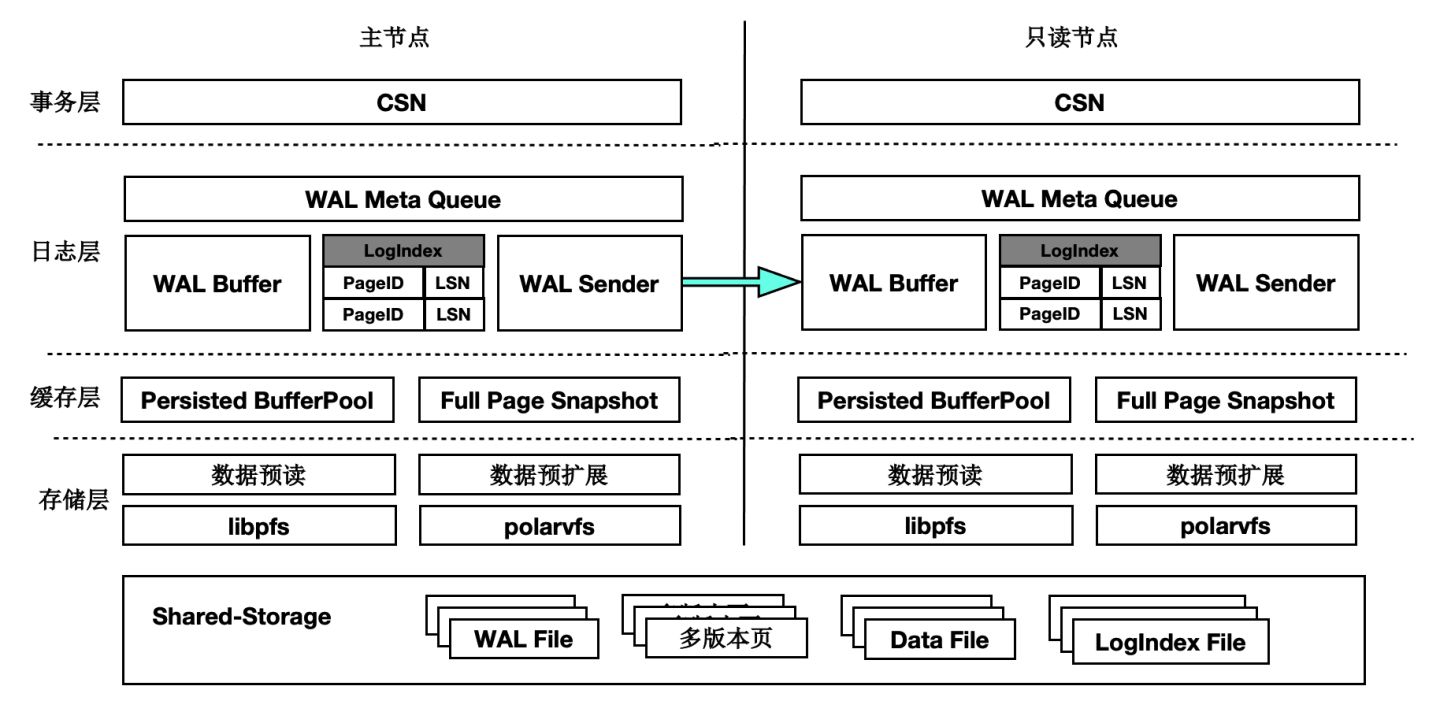
首先來看下基於Shared-Storage的PolarDB的架構原理。
- 主節點為可讀可寫節點(RW),只讀節點為只讀(RO)。
- Shared-Storage層,只有主節點能寫入,因此主節點和只讀節點能看到一致的落盤的資料。
- 只讀節點的記憶體狀態是通過回放WAL保持和主節點同步的。
- 主節點的WAL日誌寫到Shared-Storage,僅複製WAL的meta給只讀節點。
- 只讀節點從Shared-Storage上讀取WAL並回放。
資料一致性
傳統資料庫的記憶體狀態同步
傳統share nothing的資料庫,主節點和只讀節點都有自己的記憶體和儲存,只需要從主節點複製WAL日誌到只讀節點,並在只讀節點上依次回放日誌即可,這也是複製狀態機的基本原理。
基於Shared-Storage的記憶體狀態同步
前面講到過儲存計算分離後,Shared-Storage上讀取到的頁面是一致的,記憶體狀態是通過從Shared-Storage上讀取最新的WAL並回放得來,如下圖:
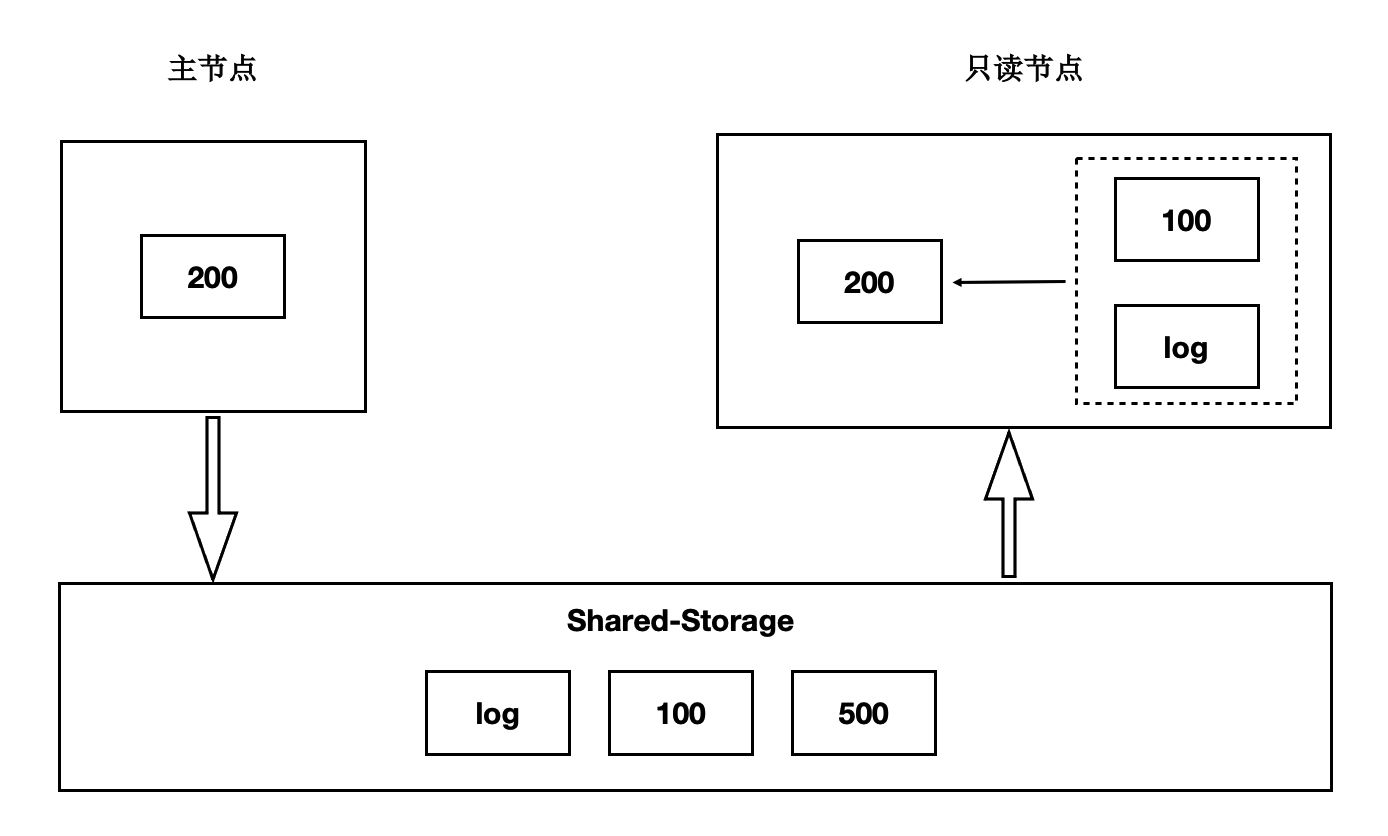
- 主節點通過刷髒把版本200寫入到Shared-Storage。
- 只讀節點基於版本100,並回放日誌得到200。
基於Shared-Storage的“過去頁面”
上述流程中,只讀節點中基於日誌回放出來的頁面會被淘汰掉,此後需要再次從儲存上讀取頁面,會出現讀取的頁面是之前的老頁面,稱為“過去頁面”。如下圖:
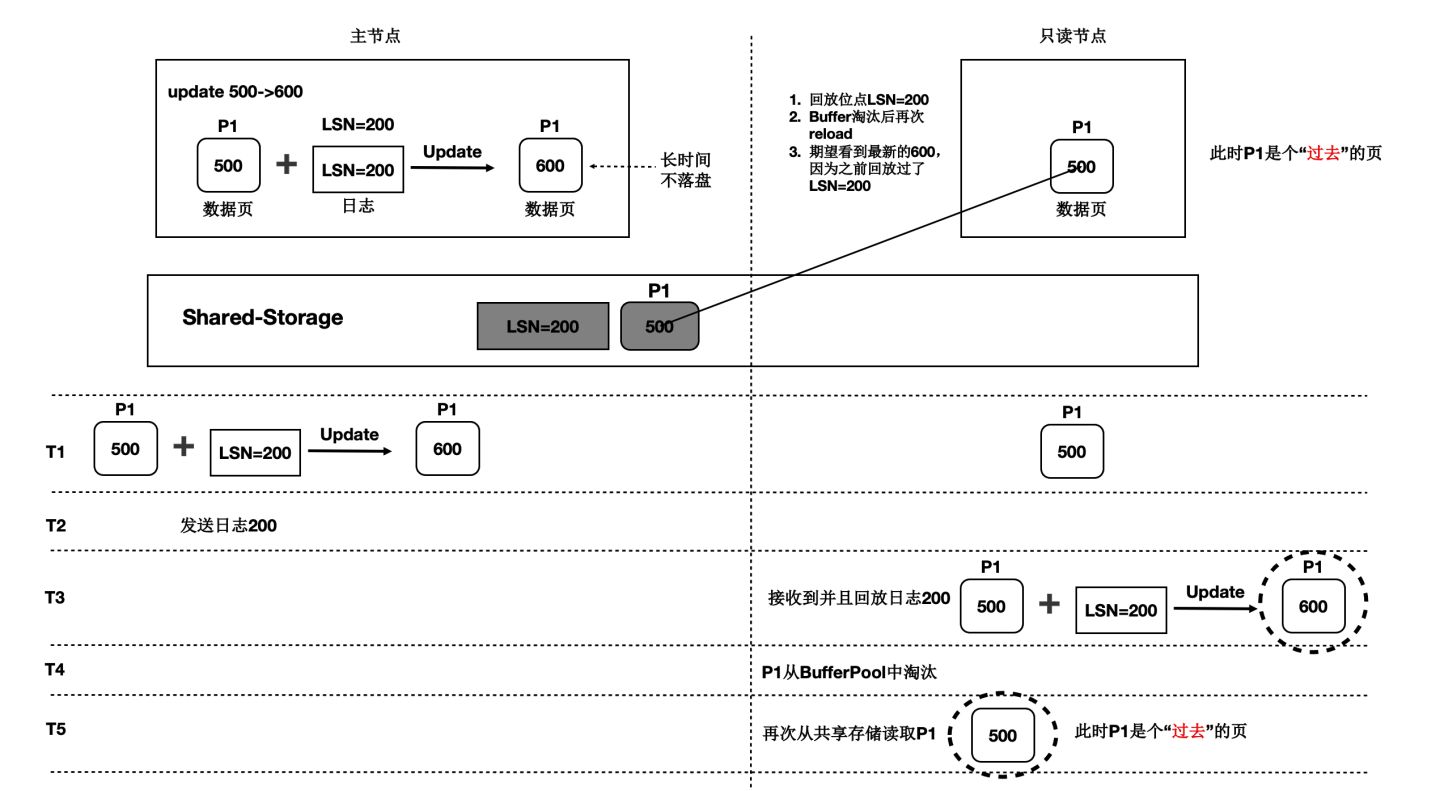
- T1時刻,主節點在T1時刻寫入日誌LSN=200,把頁面P1的內容從500更新到600;
- 只讀節點此時頁面P1的內容是500;
- T2時刻,主節點將日誌200的meta資訊傳送給只讀節點,只讀節點得知存在新的日誌;
- T3時刻,此時在只讀節點上讀取頁面P1,需要讀取頁面P1和LSN=200的日誌,進行一次回放,得到P1的最新內容為600;
- T4時刻,只讀節點上由於BufferPool不足,將回放出來的最新頁面P1淘汰掉;
- 主節點沒有將最新的頁面P1為600的最新內容刷髒到Shared-Storage上;
- T5時刻,再次從只讀節點上發起讀取P1操作,由於記憶體中已把P1淘汰掉了,因此從Shared-Storage上讀取,此時讀取到了“過去頁面”的內容;
“過去頁面” 的解法
只讀節點在任意時刻讀取頁面時,需要找到對應的Base頁面和對應起點的日誌,依次回放。如下圖:
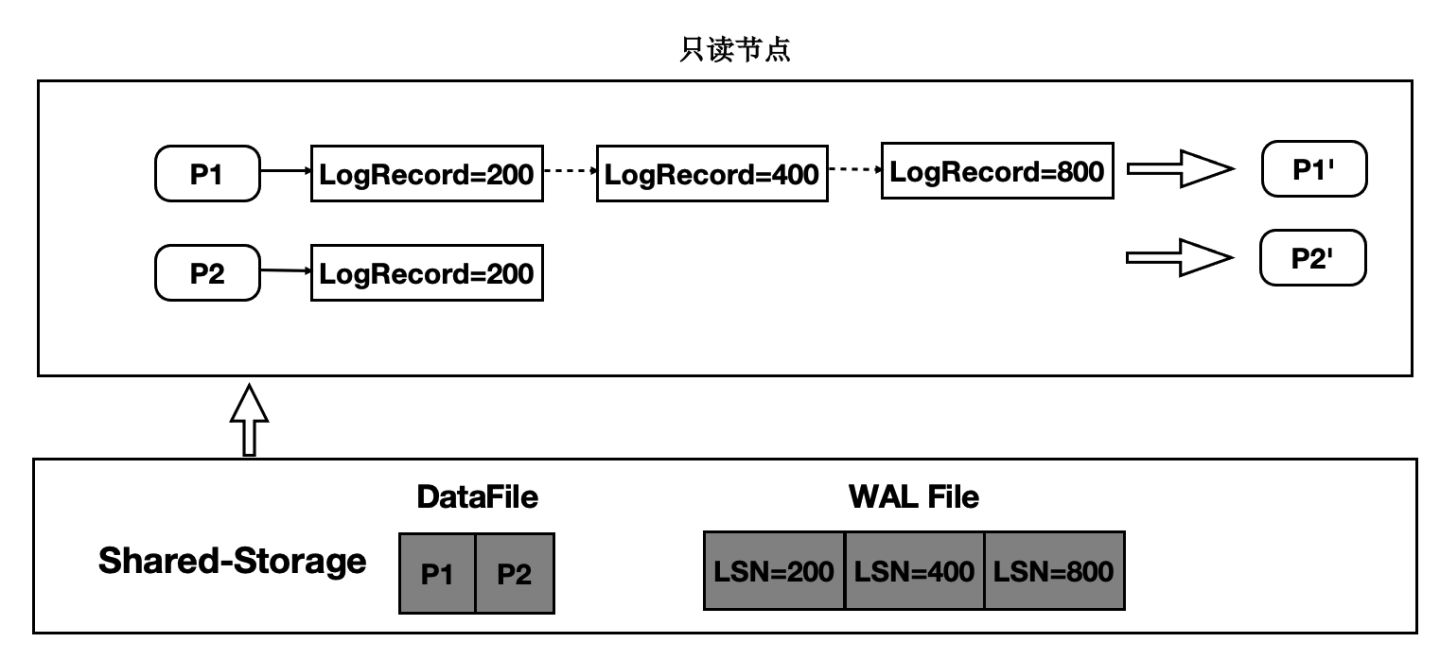
- 在只讀節點記憶體中維護每個Page對應的日誌meta。
- 在讀取時一個Page時,按需逐個應用日誌直到期望的Page版本。
- 應用日誌時,通過日誌的meta從Shared-Storage上讀取。
通過上述分析,需要維護每個Page到日誌的“倒排”索引,而只讀節點的記憶體是有限的,因此這個Page到日誌的索引需要持久化,PolarDB設計了一個可持久化的索引結構 - LogIndex。LogIndex本質是一個可持久化的hash資料結構。
- 只讀節點通過WAL receiver接收從主節點過來的WAL meta資訊。
- WAL meta記錄該條日誌修改了哪些Page。
- 將該條WAL meta插入到LogIndex中,key是PageID,value是LSN。
- 一條WAL日誌可能更新了多個Page(索引分裂),在LogIndex對有多條記錄。
- 同時在BufferPool中給該該Page打上outdate標記,以便使得下次讀取的時候從LogIndex重回放對應的日誌。
- 當記憶體達到一定閾值時,LogIndex非同步將記憶體中的hash刷到盤上。
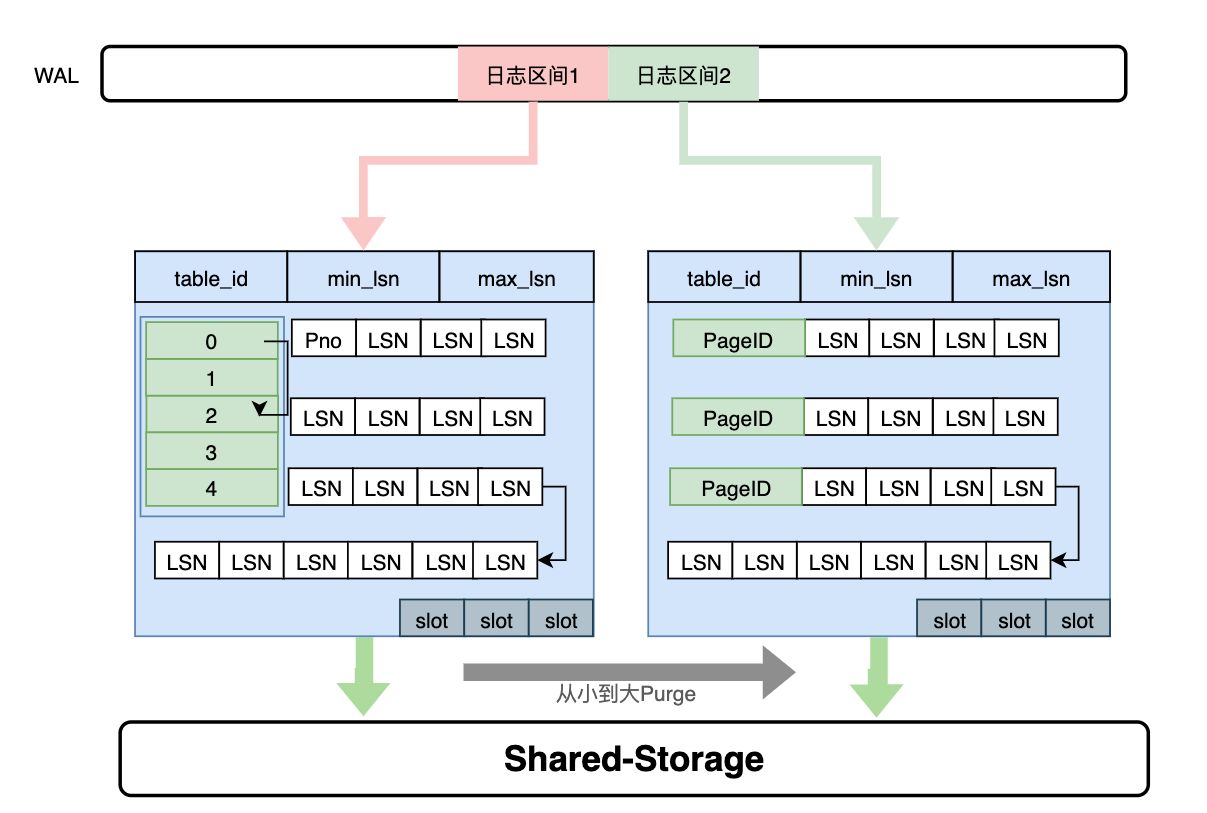
通過LogIndex解決了刷髒依賴“過去頁面”的問題,也是得只讀節點的回放轉變成了Lazy的回放:只需要回放日誌的meta資訊即可。
基於Shared-Storage的“未來頁面”
在儲存計算分離後,刷髒依賴還存在“未來頁面”的問題。如下圖所示:
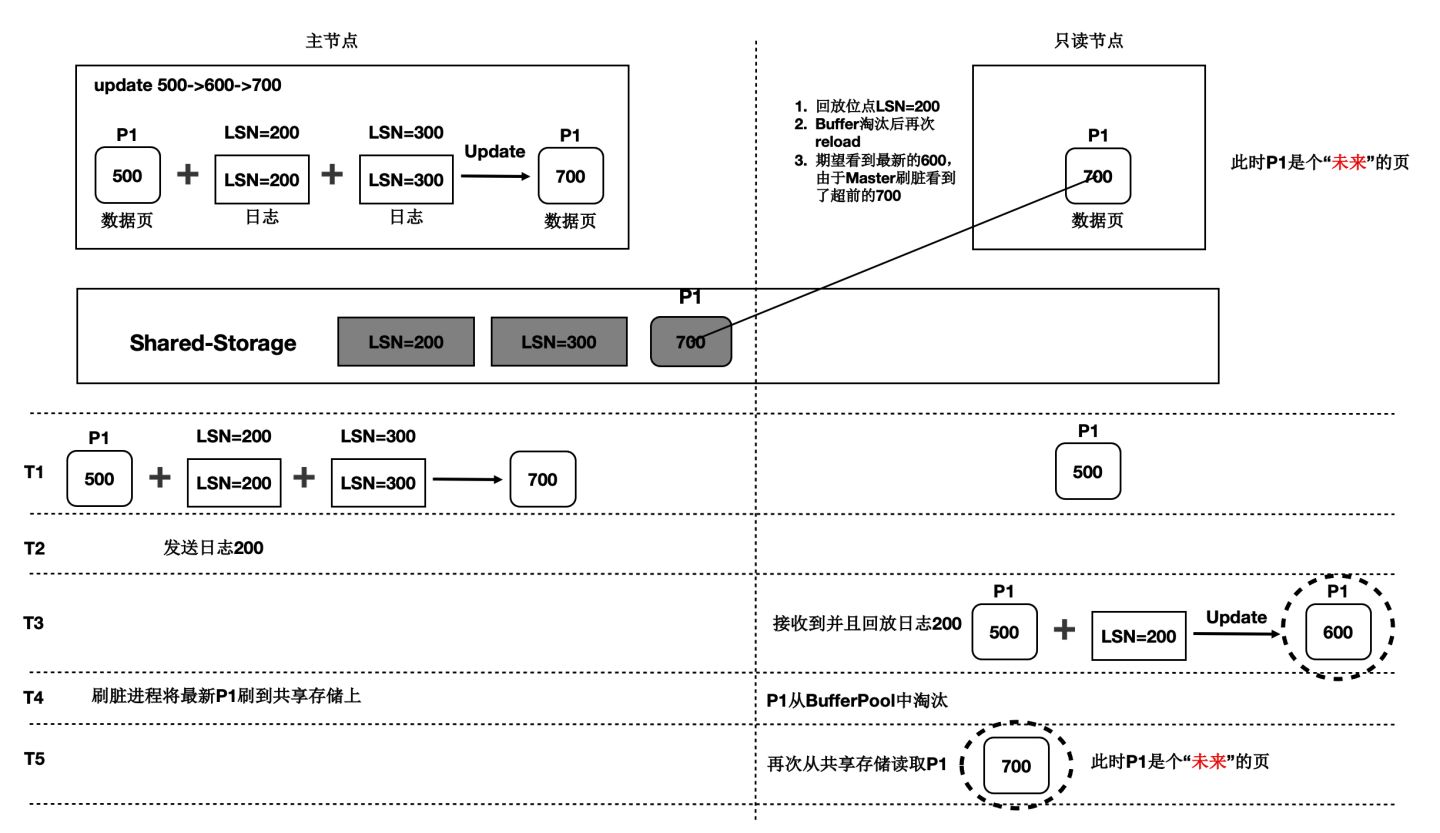
- T1時刻,主節點對P1更新了2次,產生了2條日誌,此時主節點和只讀節點上頁面P1的內容都是500。
- T2時刻, 傳送日誌LSN=200給只讀節點。
- T3時刻,只讀節點回放LSN=200的日誌,得到P1的內容為600,此時只讀節點日誌回放到了200,後面的LSN=300的日誌對他來說還不存在。
- T4時刻,主節點刷髒,將P1最新的內容700刷到了Shared-Storage上,同時只讀節點上BufferPool淘汰掉了頁面P1。
- T5時刻,只讀節點再次讀取頁面P1,由於BufferPool中不存在P1,因此從共享記憶體上讀取了最新的P1,但是隻讀節點並沒有回放LSN=300的日誌,讀取到了一個對他來說超前的“未來頁面”。
- “未來頁面”的問題是:部分頁面是未來頁面,部分頁面是正常的頁面,會到時資料不一致,比如索引分裂成2個Page後,一個讀取到了正常的Page,另一個讀取到了“未來頁面”,B+Tree的索引結構會被破壞。
“未來頁面”的解法
“未來頁面”的原因是主節點刷髒的速度超過了任一隻讀節點的回放速度(雖然只讀節點的Lazy回放已經很快了)。因此,解法就是對主節點刷髒進度時做控制:不能超過最慢的只讀節點的回放位點。如下圖所示:

- 只讀節點回放到T4位點。
- 主節點在刷髒時,對所有髒頁按照LSN排序,僅刷在T4之前的髒頁(包括T4),之後的髒頁不刷。
- 其中,T4的LSN位點稱為“一致性位點”。
低延遲複製
傳統流複製的問題
- 同步鏈路:日誌同步路徑IO多,網路傳輸量大。
- 頁面回放:讀取和Buffer修改慢(IO密集型 + CPU密集型)。
- DDL回放:修改檔案時需要對修改的檔案加鎖,而加鎖的過程容易被阻塞,導致DDL慢。
- 快照更新:RO高併發引起事務快照更新慢。
如下圖所示:
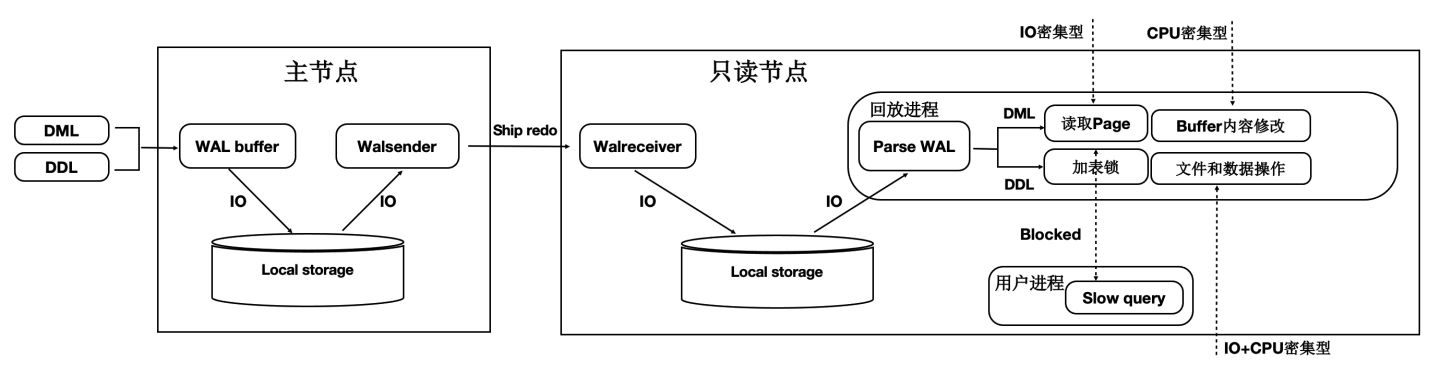
- 主節點寫入WAL日誌到本地檔案系統中。
- WAL Sender程序讀取,併發送。
- 只讀節點的WAL Receiver程序接收寫入到本地檔案系統中。
- 回放程序讀取WAL日誌,讀取對應的Page到BufferPool中,並在記憶體中回放。
- 主節點刷髒頁到Shared Storage。
可以看到,整個鏈路是很長的,只讀節點延遲高,影響使用者業務讀寫分離負載均衡。
優化1 - 只複製Meta
因為底層是Shared-Storage,只讀節點可直接從Shared-Storage上讀取所需要的WAL資料。因此主節點只把WAL日誌的元資料(去掉Payload)複製到只讀節點,這樣網路傳輸量小,減少關鍵路徑上的IO。如下圖所示:
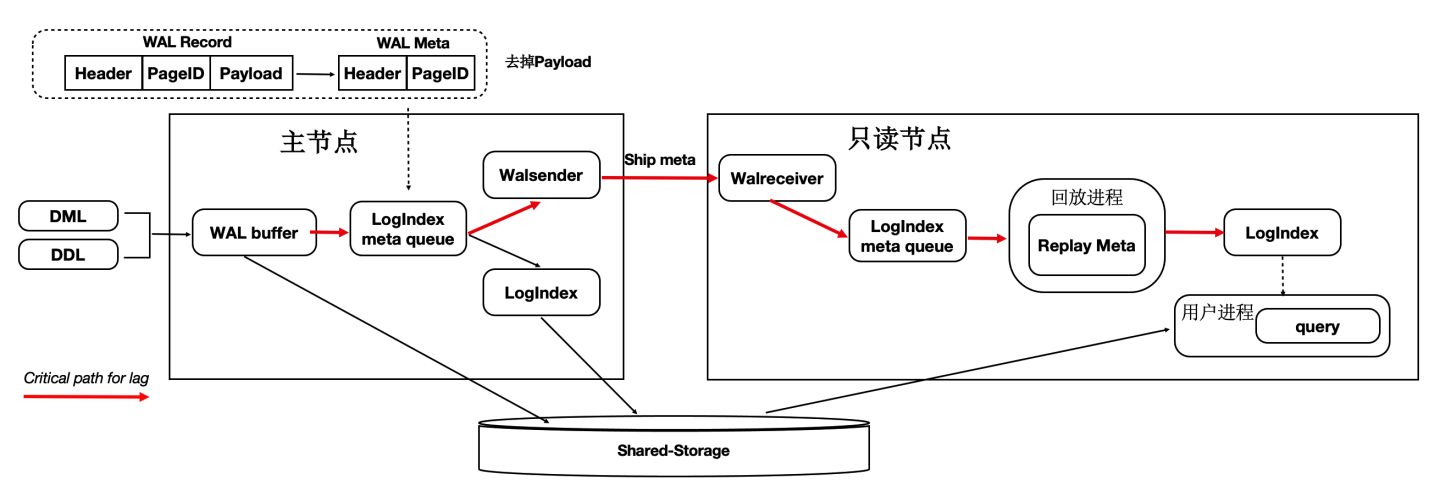
- WAL Record是由:Header,PageID,Payload組成。
- 由於只讀節點可以直接讀取Shared-Storage上的WAL檔案,因此主節點只把 WAL 日誌的元資料傳送(複製)到只讀節點,包括:Header,PageID。
- 在只讀節點上,通過WAL的元資料直接讀取Shared-Storage上完整的WAL檔案。
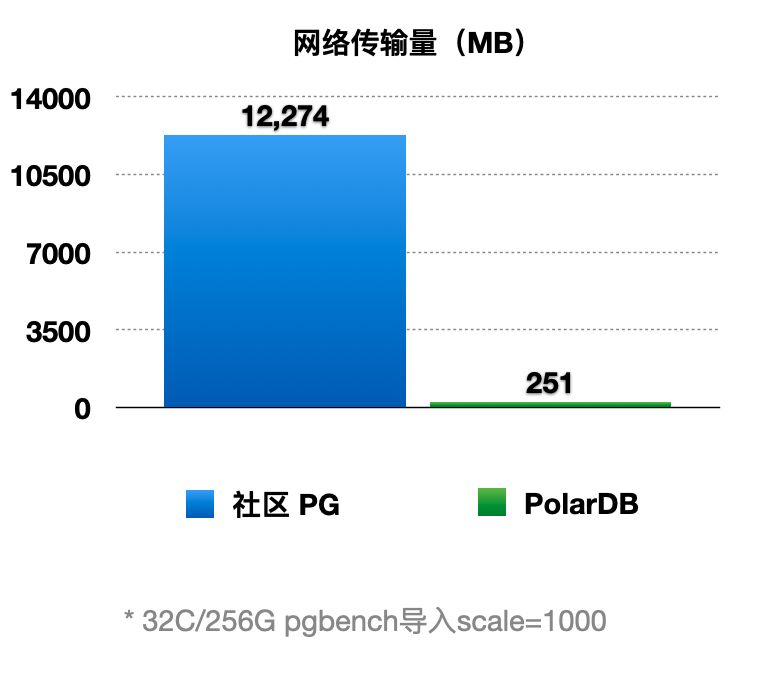
通過上述優化,能顯著減少主節點和只讀節點間的網路傳輸量。從下圖可以看到網路傳輸量減少了98%。
優化2 - 頁面回放優化
在傳統DB中日誌回放的過程中會讀取大量的Page並逐個日誌Apply,然後落盤。該流程在使用者讀IO的關鍵路徑上,藉助儲存計算分離可以做到:如果只讀節點上Page不在BufferPool中,不產生任何IO,僅僅記錄LogIndex即可。
可以將回放程序中的如下IO操作offload到session程序中:
- 資料頁IO開銷。
- 日誌apply開銷。
- 基於LogIndex頁面的多版本回放。
如下圖所示,在只讀節點上的回放程序中,在Apply一條WAL的meta時:
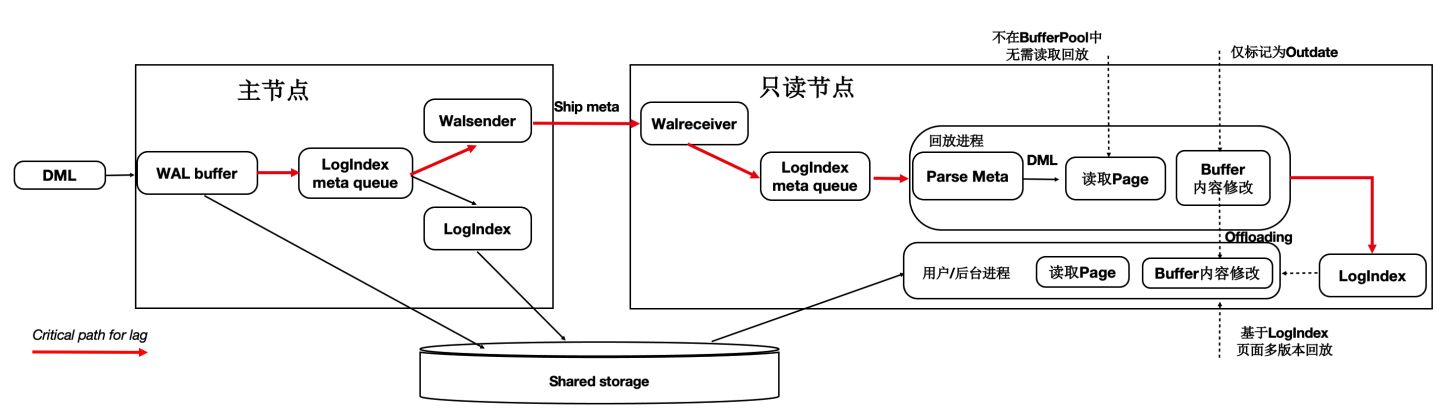
- 如果對應Page不在記憶體中,僅僅記錄LogIndex。
- 如果對應的Page在記憶體中,則標記為Outdate,並記錄LogIndex,回放過程完成。
- 使用者session程序在讀取Page時,讀取正確的Page到BufferPool中,並通過LogIndex來回放相應的日誌。
- 可以看到,主要的IO操作有原來的單個回放程序offload到了多個使用者程序。
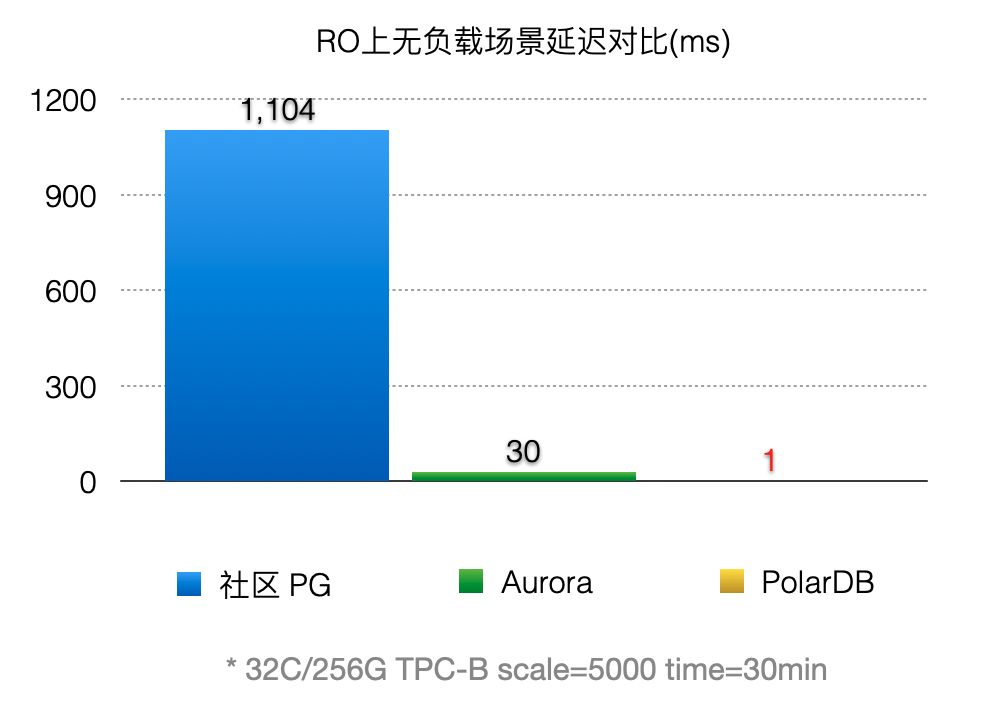
通過上述優化,能顯著減少回放的延遲,比AWS Aurora快30倍。
優化3 - DDL鎖回放優化
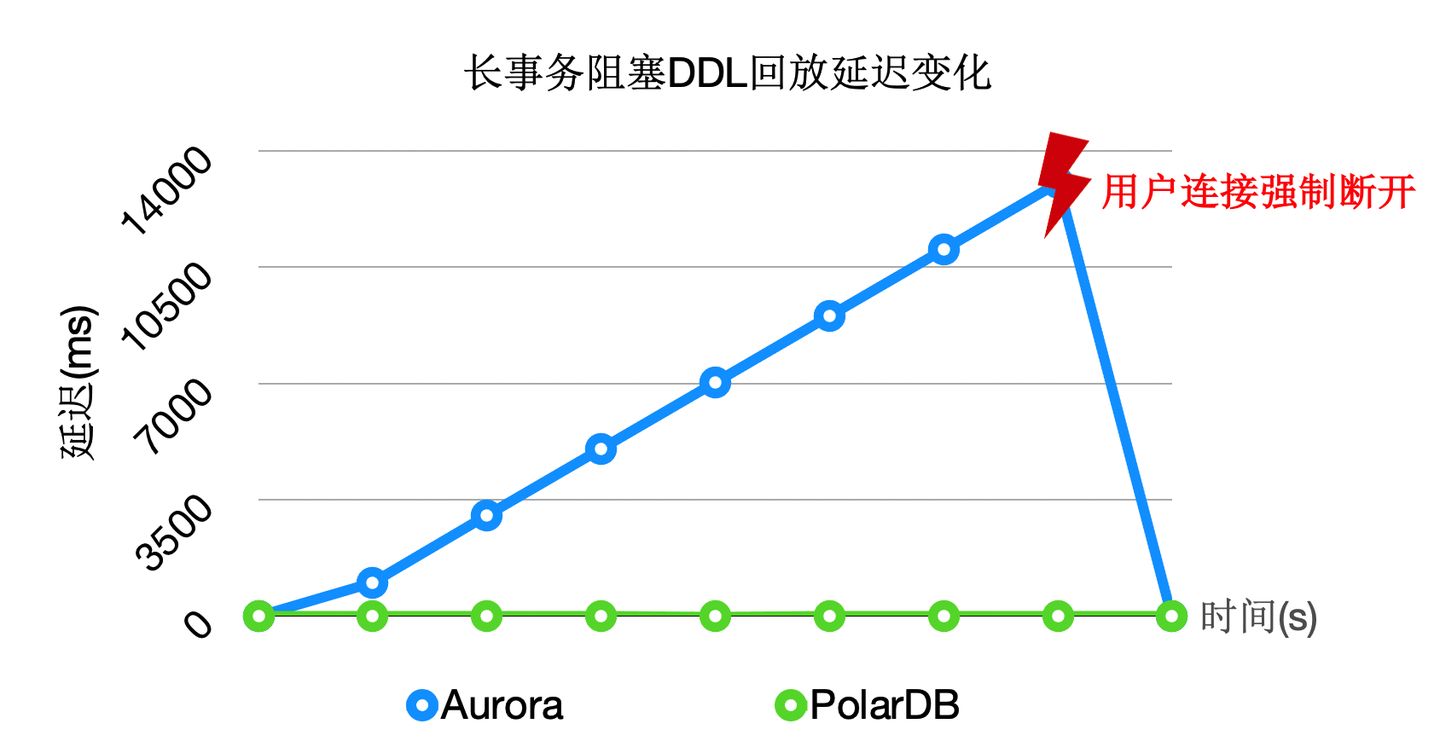
在主節點執行DDL時,比如:drop table,需要在所有節點上都對錶上排他鎖,這樣能保證表文件不會在只讀節點上讀取時被主節點刪除掉了(因為檔案在Shared-Storage上只有一份)。在所有隻讀節點上對錶上排他鎖是通過WAL複製到所有的只讀節點,只讀節點回放DDL鎖來完成。
而回放程序在回放DDL鎖時,對錶上鎖可能會阻塞很久,因此可以通過把DDL鎖也offload到其他程序上來優化回訪程序的關鍵路徑。

通過上述優化,能夠回放程序一直處於平滑的狀態,不會因為去等DDL而阻塞了回放的關鍵路徑。
上述3個優化之後,極大的降低了複製延遲,能夠帶來如下優勢:
- 讀寫分離:負載均衡,更接近Oracle RAC使用體驗。
- 高可用:加速HA流程。
- 穩定性:最小化未來頁的數量,可以寫更少或者無需寫頁面快照。
Recovery優化
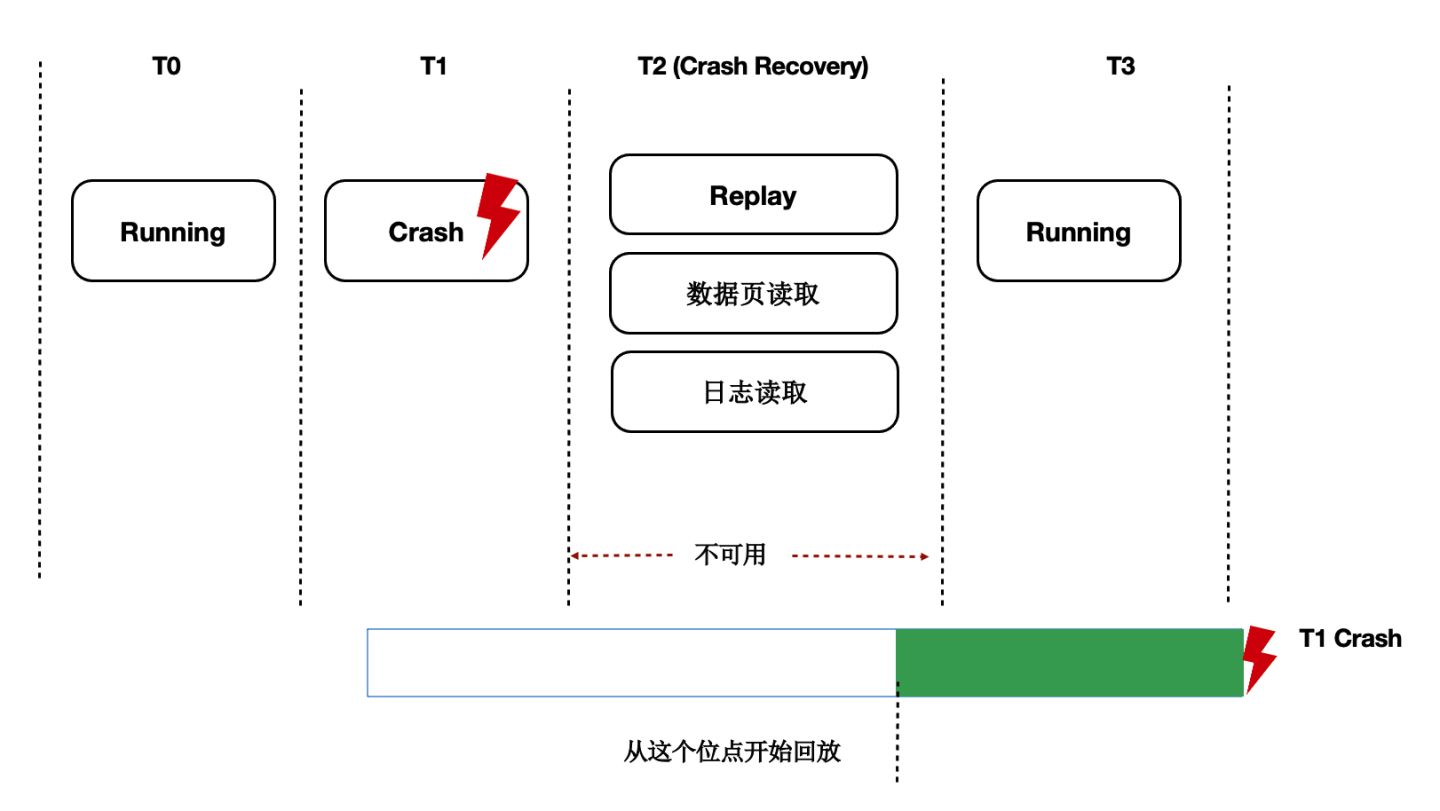
背景
資料庫OOM、Crash等場景恢復時間長,本質上是日誌回放慢,在共享儲存Direct-IO模型下問題更加突出。
Lazy Recovery
前面講到過通過LogIndex我們在只讀節點上做到了Lazy的回放,那麼在主節點重啟後的recovery過程中,本質也是在回放日誌,那麼我們可以藉助Lazy回放來加速recovery的過程:
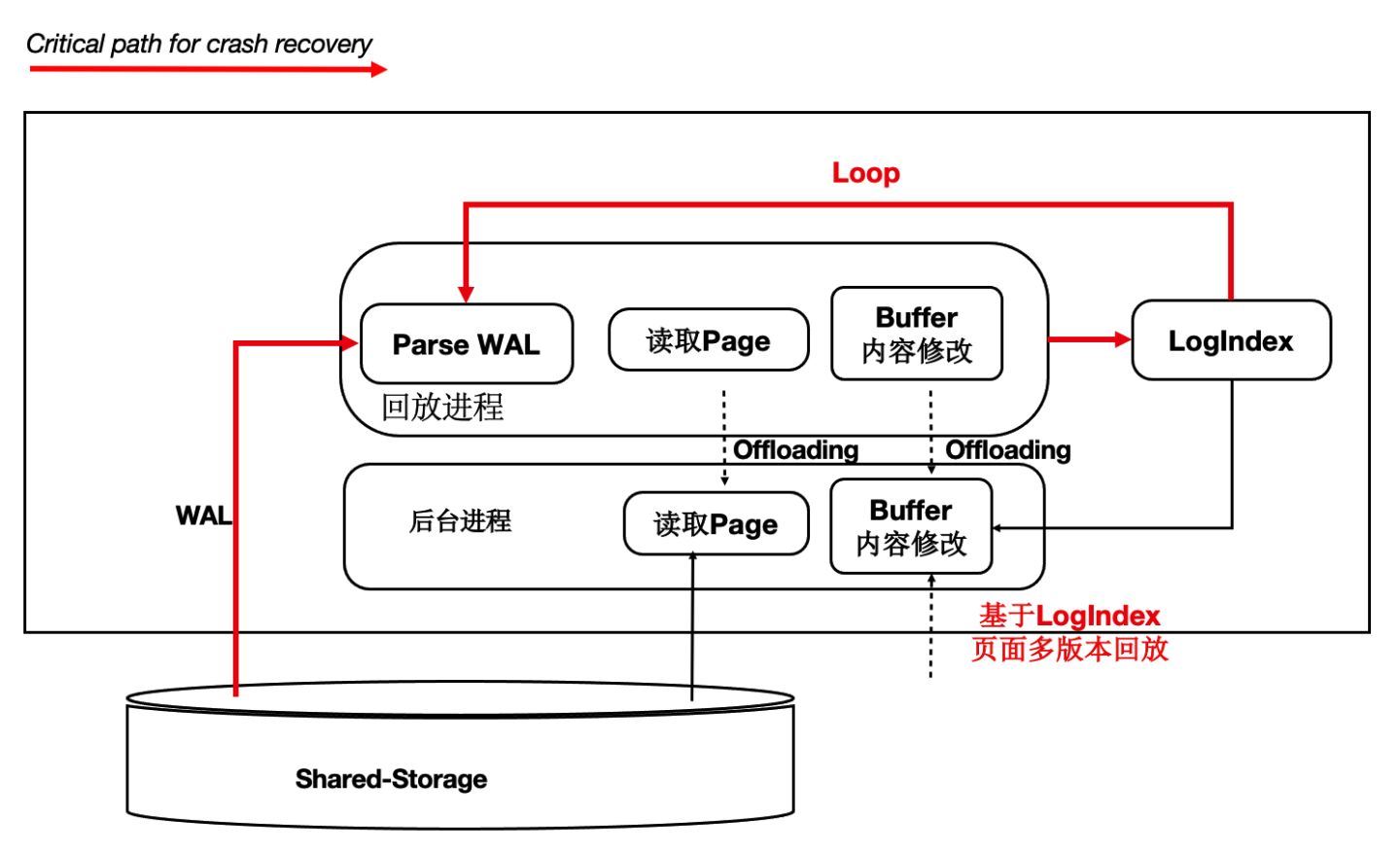
- 從checkpoint點開始逐條去讀WAL日誌。
- 回放完LogIndex日誌後,即認為回放完成。
- recovery完成,開始提供服務。
- 真正的回放被offload到了重啟之後進來的session程序中。
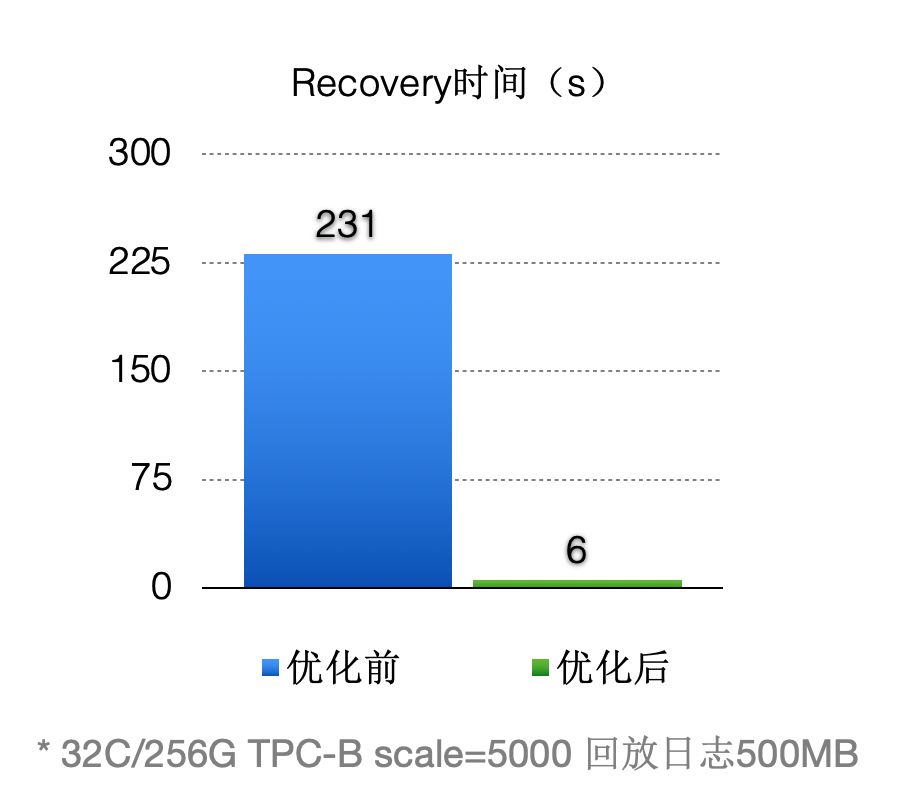
優化之後(回放500MB日誌量):
Persistent BufferPool
上述方案優化了在recovery的重啟速度,但是在重啟之後,session程序通過讀取WAL日誌來回放想要的page。表現就是在recovery之後會有短暫的響應慢的問題。優化的辦法為在資料庫重啟時BufferPool並不銷燬,如下圖所示:crash和restart期間BufferPool不銷燬。
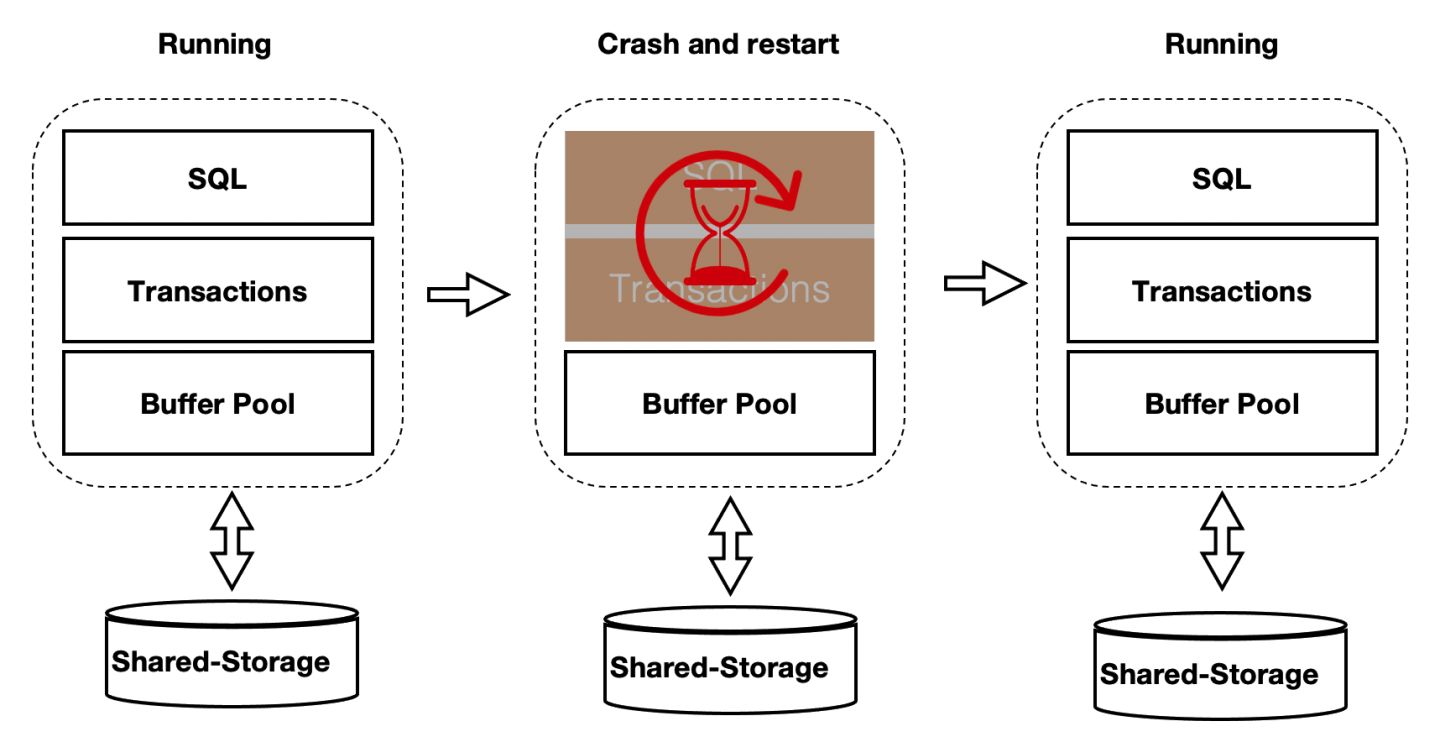
核心中的共享記憶體分成2部分:
- 全域性結構,ProcArray等。
- BufferPool結構;其中BufferPool通過具名共享記憶體來分配,在程序重啟後仍然有效。而全域性結構在程序重啟後需要重新初始化。

而BufferPool中並不是所有的Page都是可以複用的,比如:在重啟前,某程序對Page上X鎖,隨後crash了,該X鎖就沒有程序來釋放了。因此,在crash和restart之後需要把所有的BufferPool遍歷一遍,剔除掉不能被複用的Page。另外,BufferPool的回收依賴k8s。
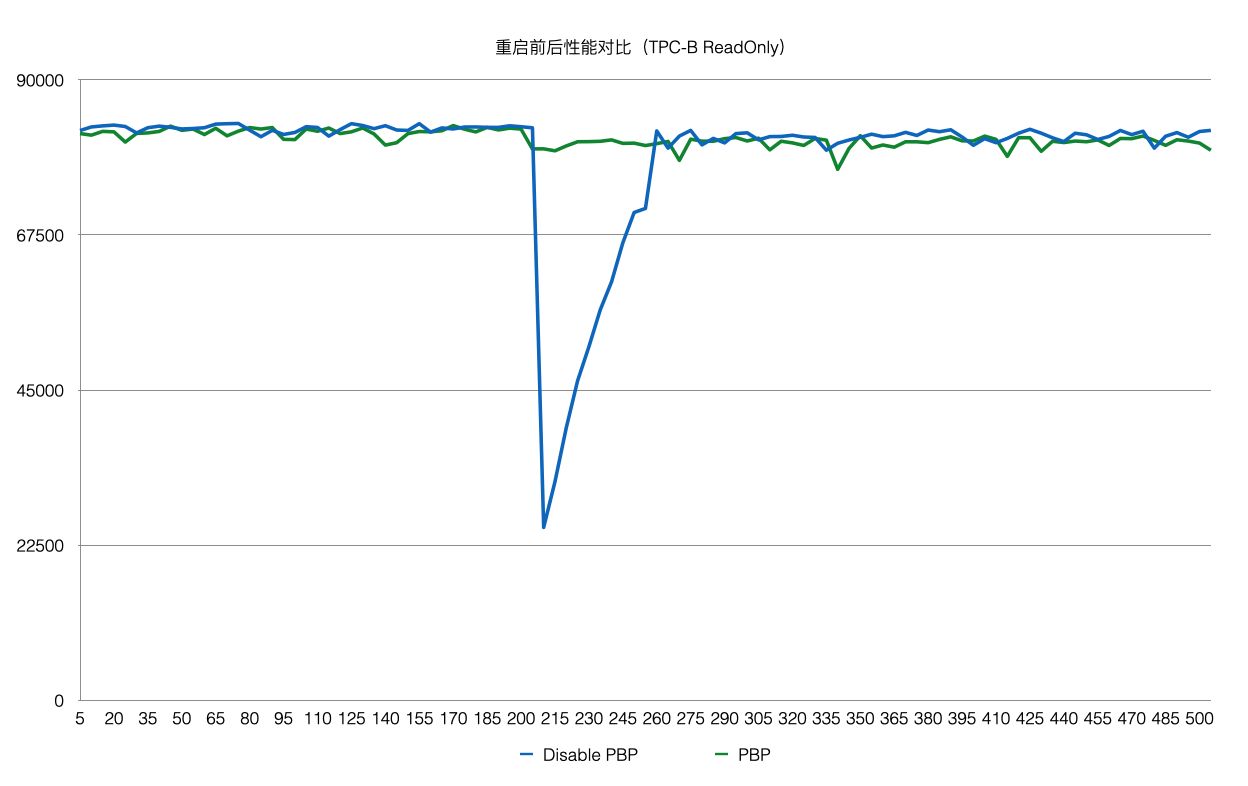
該優化之後,使得重啟前後效能平穩。
PolarDB - HTAP架構
PolaDB讀寫分離後,由於底層是儲存池,理論上IO吞吐是無限大的。而大查詢只能在單個計算節點上執行,單個計算節點的CPU/MEM/IO是有限的,因此單個計算節點無法發揮出儲存側的大IO頻寬的優勢,也無法通過增加計算資源來加速大的查詢。我們研發了基於Shared-Storage的MPP分散式並行執行,來加速在OLTP場景下OLAP查詢。
HTAP架構原理
PolarDB底層儲存在不同節點上是共享的,因此不能直接像傳統MPP一樣去掃描表。我們在原來單機執行引擎上支援了MPP分散式並行執行,同時對Shared-Storage進行了優化。 基於Shared-Storage的MPP是業界首創,它的原理是:
- Shuffle運算元遮蔽資料分佈。
- ParallelScan運算元遮蔽共享儲存。
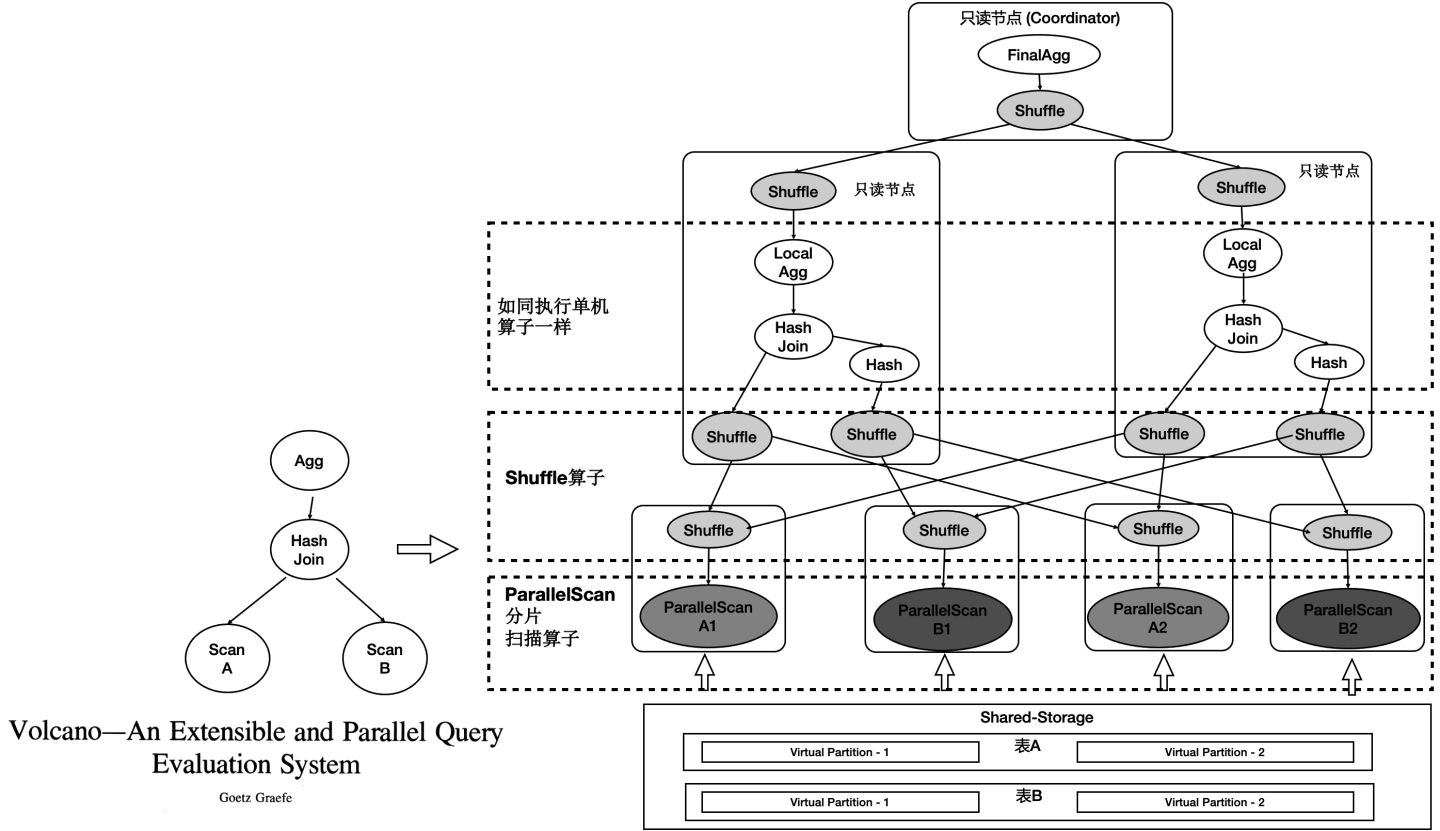
如圖所示:
- 表A和表B做join,並做聚合。
- 共享儲存中的表仍然是單個表,並沒有做物理上的分割槽。
- 重新設計4類掃描運算元,使之在掃描共享儲存上的表時能夠分片掃描,形成virtual partition。
分散式優化器
基於社群的GPORCA優化器擴充套件了能感知共享儲存特性的Transformation Rules。使得能夠探索共享儲存下特有的Plan空間,比如:對於一個表在PolarDB中既可以全量的掃描,也可以分割槽域掃描,這個是和傳統MPP的本質區別。
圖中,上面灰色部分是PolarDB核心與GPORCA優化器的適配部分。
下半部分是ORCA核心,灰色模組是我們在ORCA核心中對共享儲存特性所做的擴充套件。
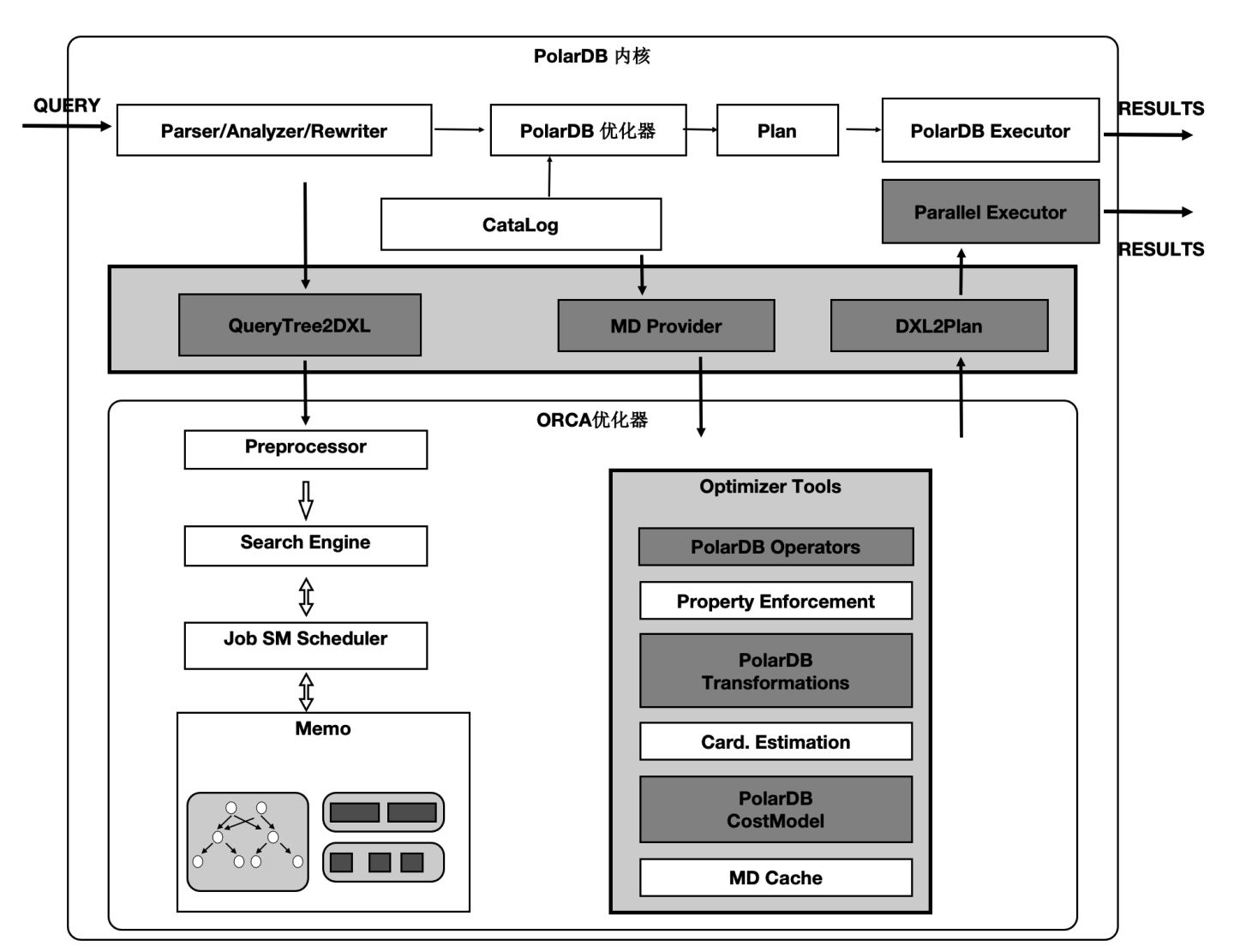
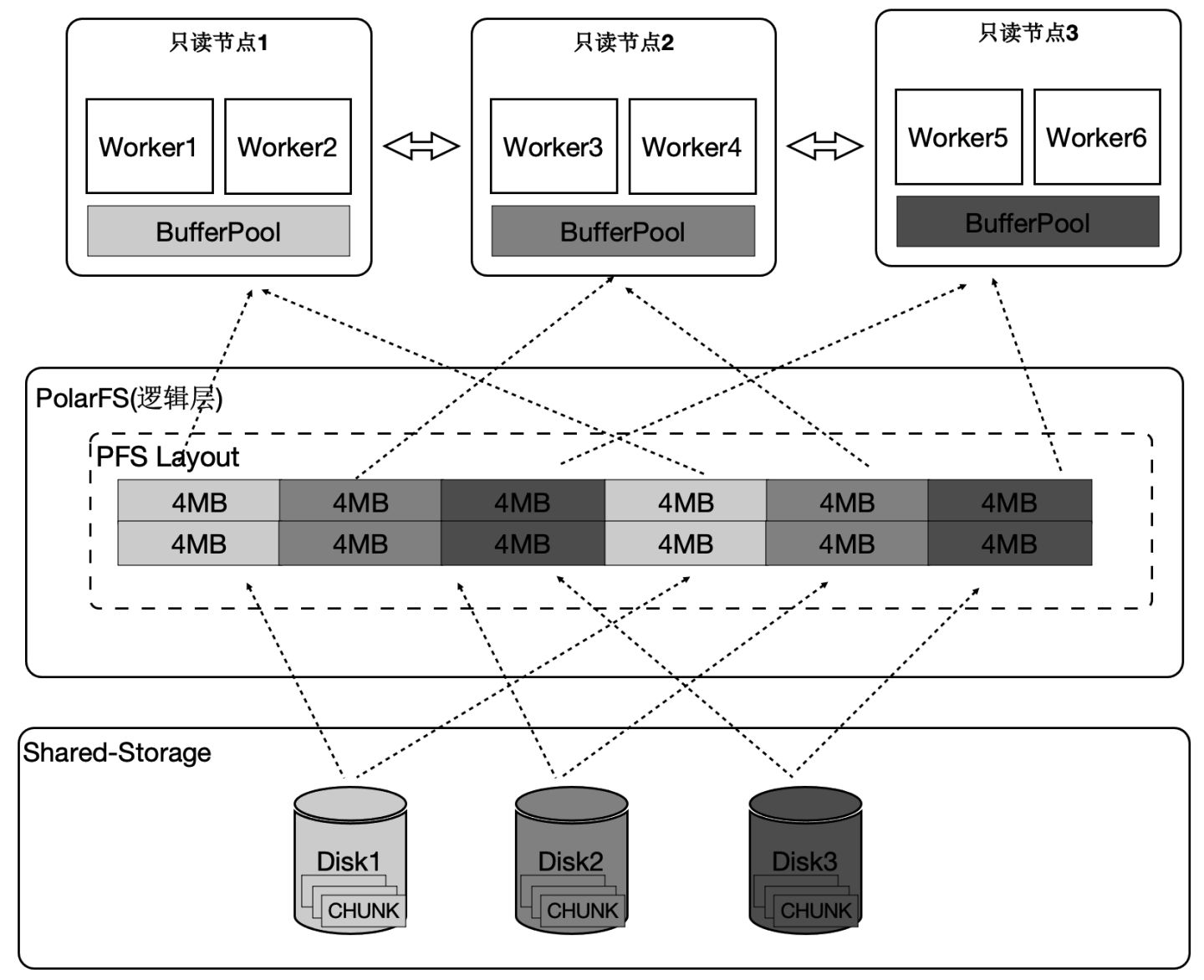
運算元並行化
PolarDB中有4類運算元需要並行化,下面介紹一個具有代表性的Seqscan的運算元的並行化。為了最大限度的利用儲存的大IO頻寬,在順序掃描時,按照4MB為單位做邏輯切分,將IO儘量打散到不同的盤上,達到所有的盤同時提供讀服務的效果。這樣做還有一個優勢,就是每個只讀節點只掃描部分表文件,那麼最終能快取的表大小是所有隻讀節點的BufferPool總和。
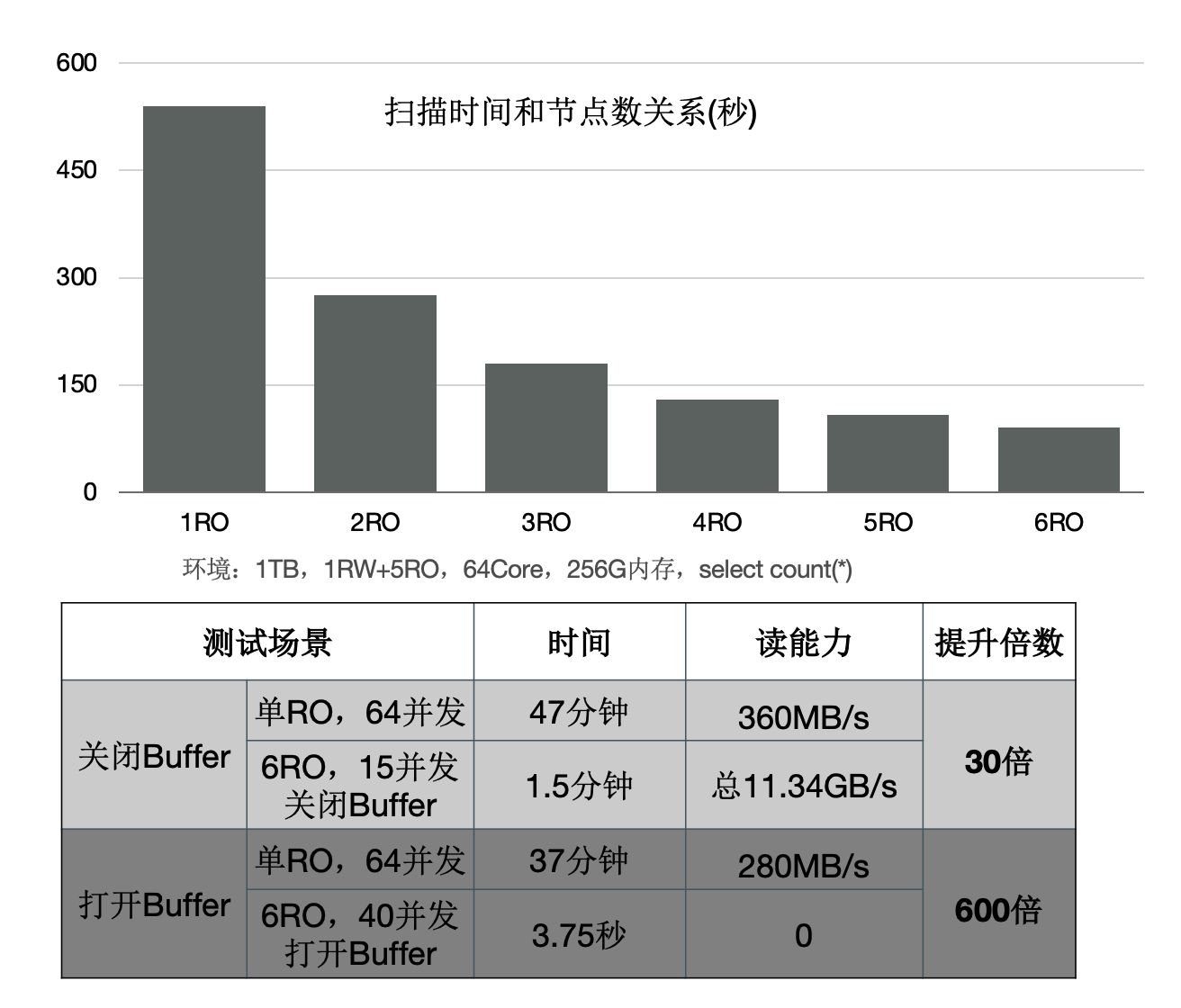
下面的圖表中:
- 增加只讀節點,掃描效能線性提升30倍。
- 開啟Buffer時,掃描從37分鐘降到3.75秒。
消除資料傾斜問題
傾斜是傳統MPP固有的問題:
- 在PolarDB中,大物件的是通過heap表關聯TOAST表,無論對哪個表切分都無法達到均衡。
- 另外,不同只讀節點的事務、buffer、網路、IO負載抖動。
以上兩點會導致分佈執行時存在長尾程序。
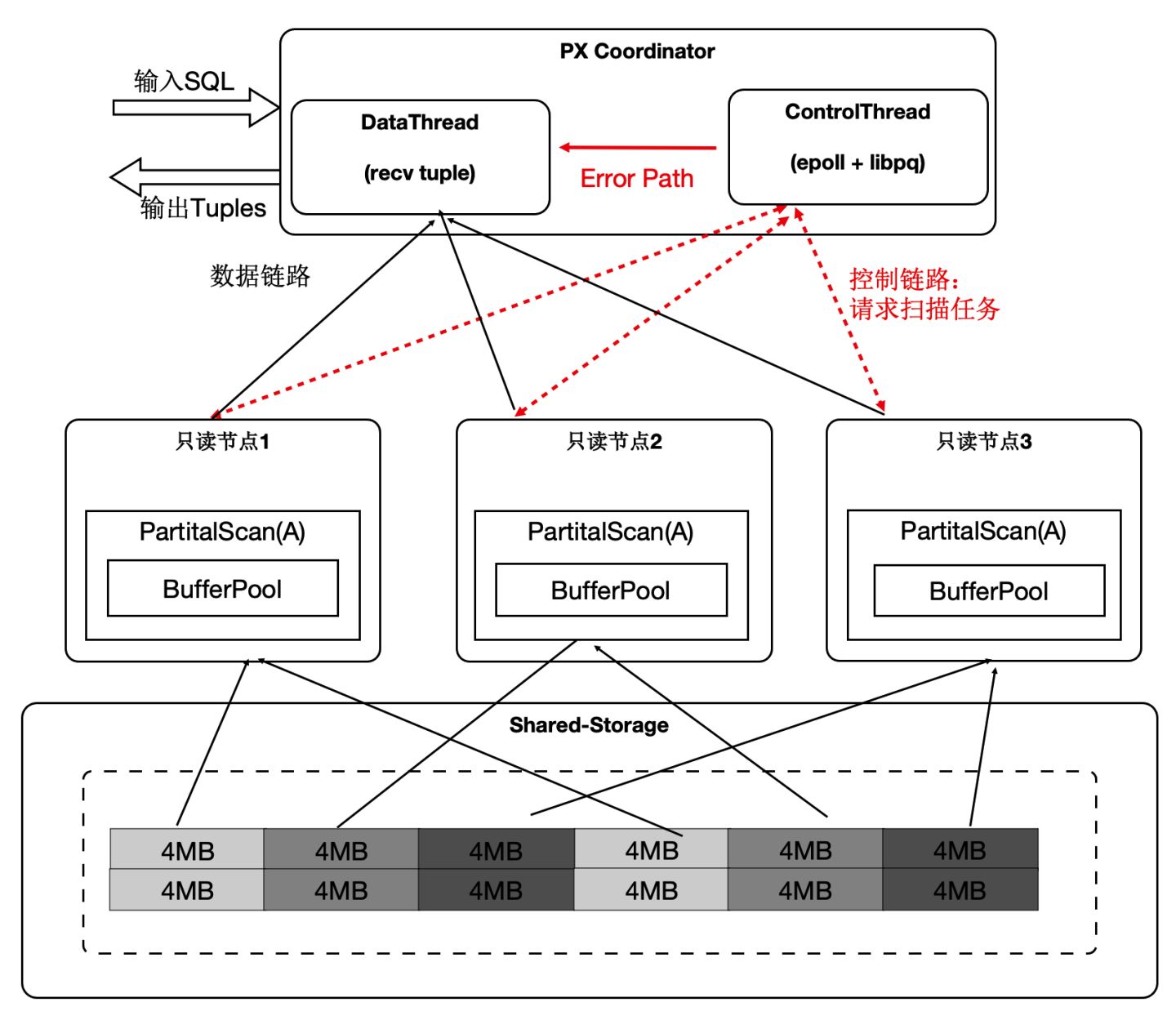
- 協調節點內部分成DataThread和ControlThread。
- DataThread負責收集彙總元組。
- ControlThread負責控制每個掃描運算元的掃描進度。
- 掃描快的工作程序能多掃描邏輯的資料切片。
- 過程中需要考慮Buffer的親和性。
需要注意的是:儘管是動態分配,儘量維護buffer的親和性;另外,每個運算元的上下文儲存在worker的私有記憶體中,Coordinator不儲存具體表的資訊;
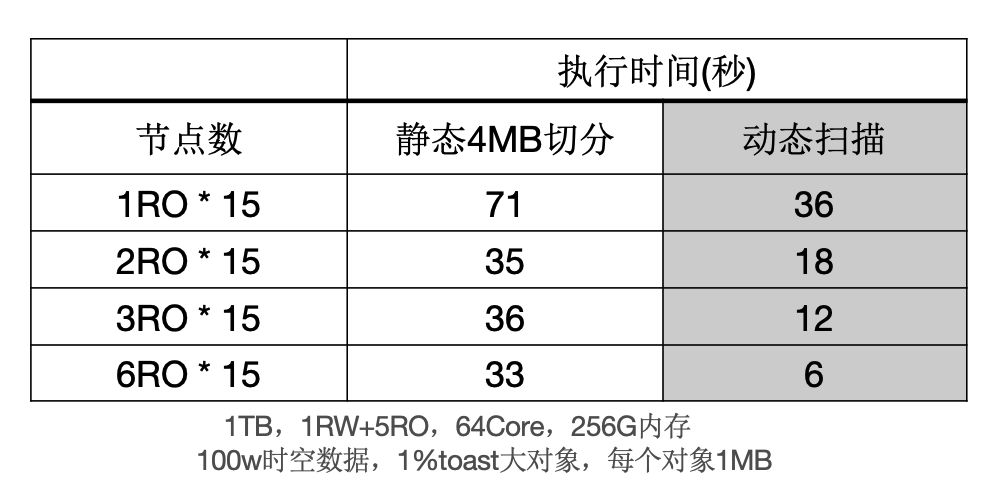
下面表格中,當出現大物件時,靜態切分出現資料傾斜,而動態掃描仍然能夠線性提升。
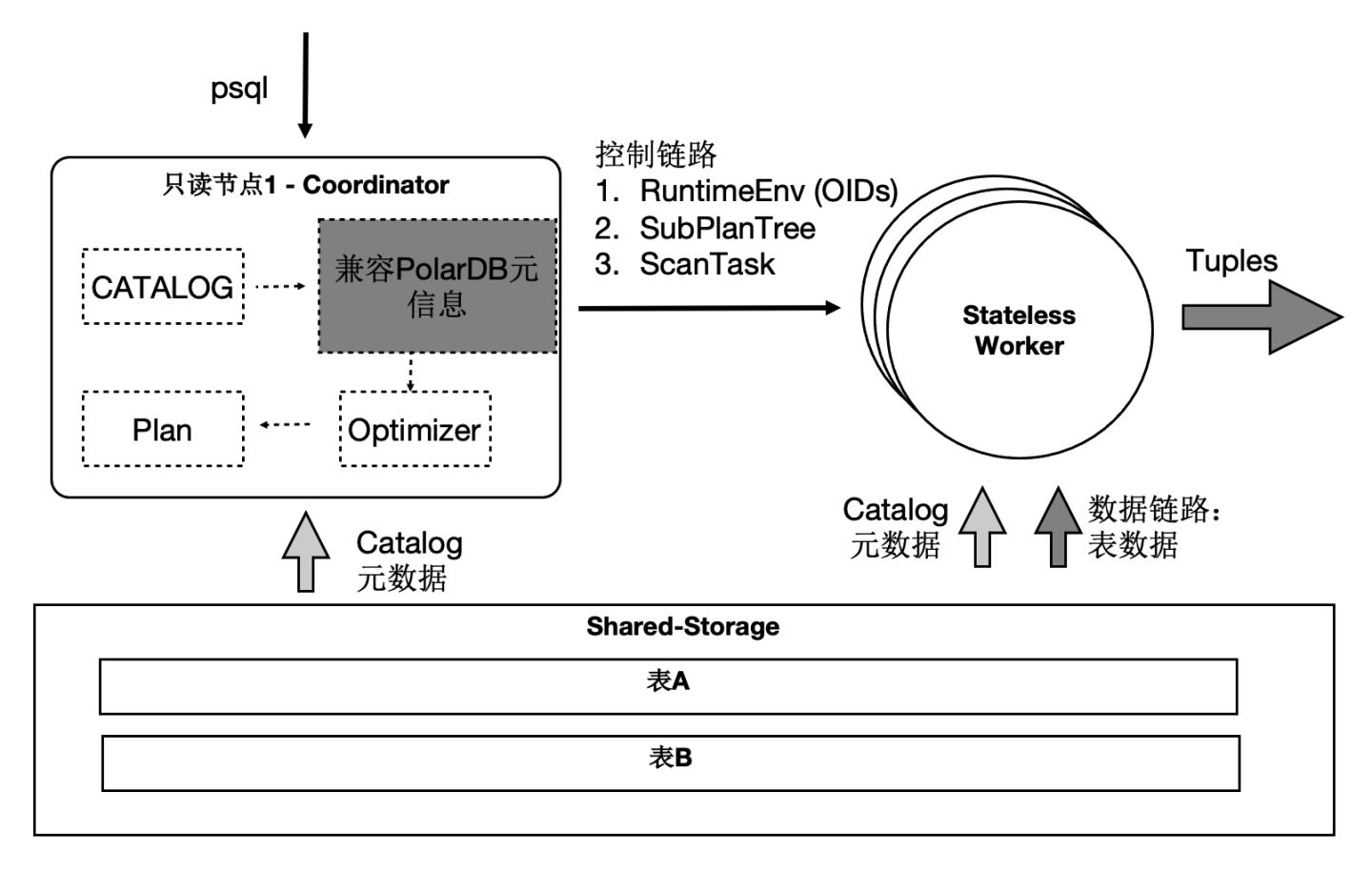
SQL級別彈性擴充套件
那我們利用資料共享的特點,還可以支援雲原生下極致彈性的要求:把Coordinator全鏈路上各個模組所需要的外部依賴存在共享儲存上,同時worker全鏈路上需要的執行時引數通過控制鏈路從Coordinator同步過來,使Coordinator和worker無狀態化。
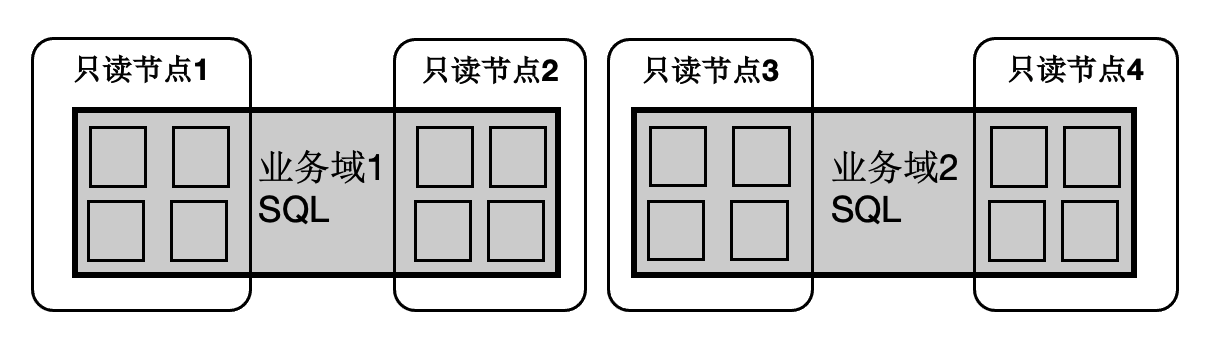
因此:
- SQL連線的任意只讀節點都可以成為Coordinator節點,這解決了Coordinator單點問題。
- 一個SQL能在任意節點上啟動任意worker數目,達到算力能SQL級別彈性擴充套件,也允許業務有更多的排程策略:不同業務域同時跑在不同的節點集合上。
事務一致性
多個計算節點資料一致性通過等待回放和globalsnapshot機制來完成。等待回放保證所有worker能看到所需要的資料版本,而globalsnapshot保證了選出一個統一的版本。

TPCH效能 - 加速比
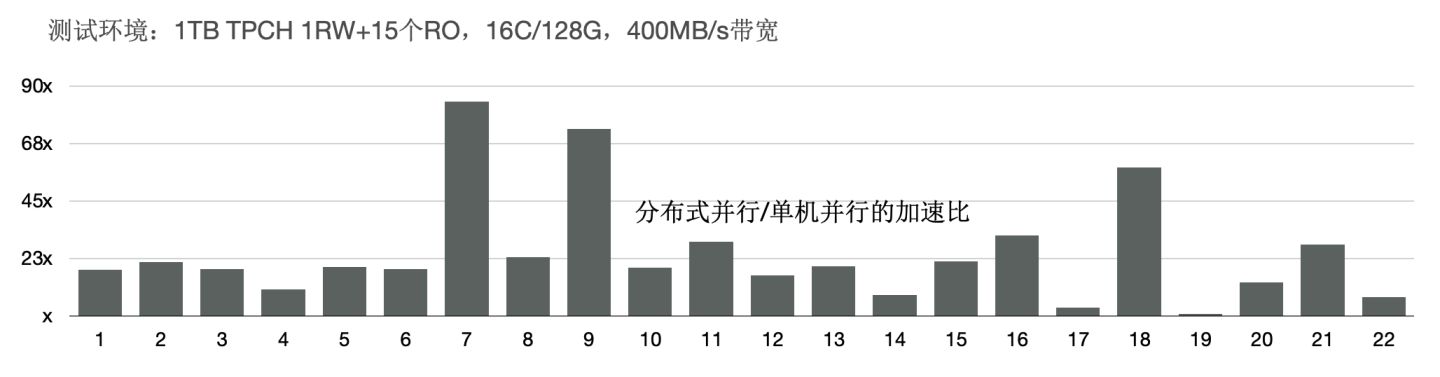
我們使用1TB的TPCH進行了測試,首先對比了PolarDB新的分散式並行和單機並行的效能:有3個SQL提速60倍,19個SQL提速10倍以上;
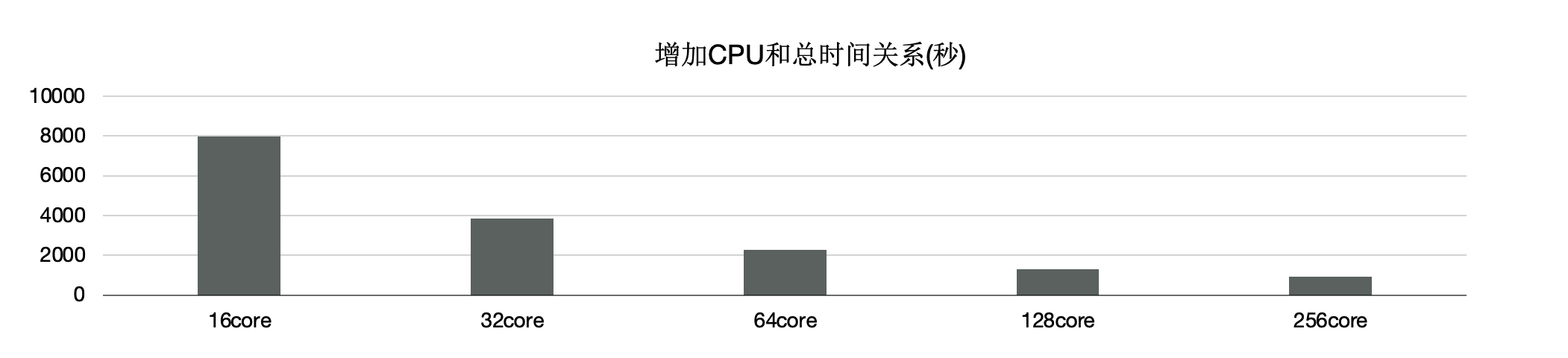
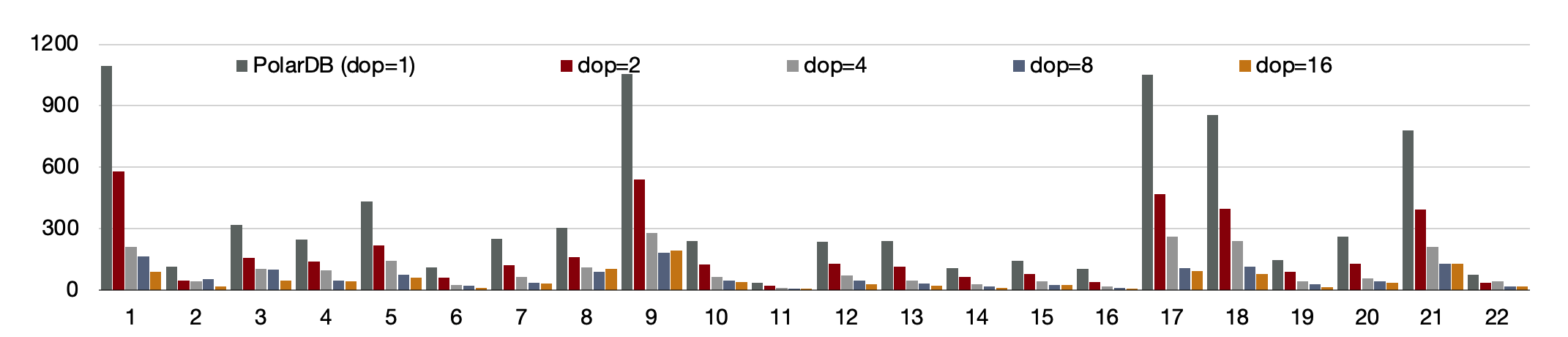
另外,使用分散式執行引擎測,試增加CPU時的效能,可以看到,從16核和128核時效能線性提升; 單看22條SQL,通過該增加CPU,每個條SQL效能線性提升。
TPCH效能 - 和Greenplum的對比
和傳統MPP的Greenplum的對比,同樣使用16個節點,PolarDB的效能是Greenplum的90%。


前面講到我們給PolarDB的分散式引擎做到了彈性擴充套件,資料不需要充分重分佈,當dop=8時,效能是Greenplum的5.6倍。
分散式執行加速索引建立
OLTP業務中會建大量的索引,經分析建索引過程中:80%是在排序和構建索引頁,20%在寫索引頁。通過使用分散式並行來加速排序過程,同時流水化批量寫入。
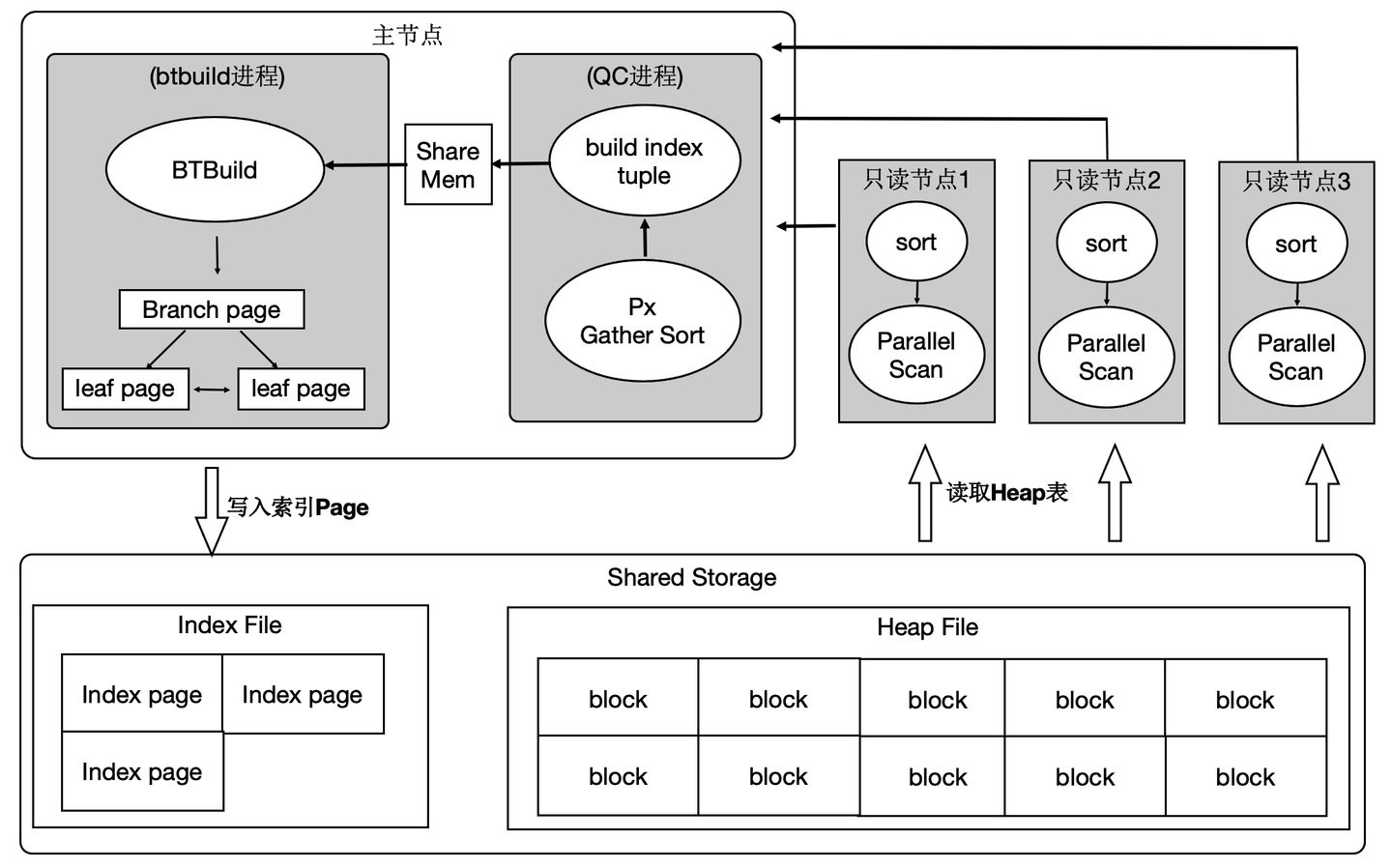
上述優化能夠使得建立索引有4~5倍的提升。
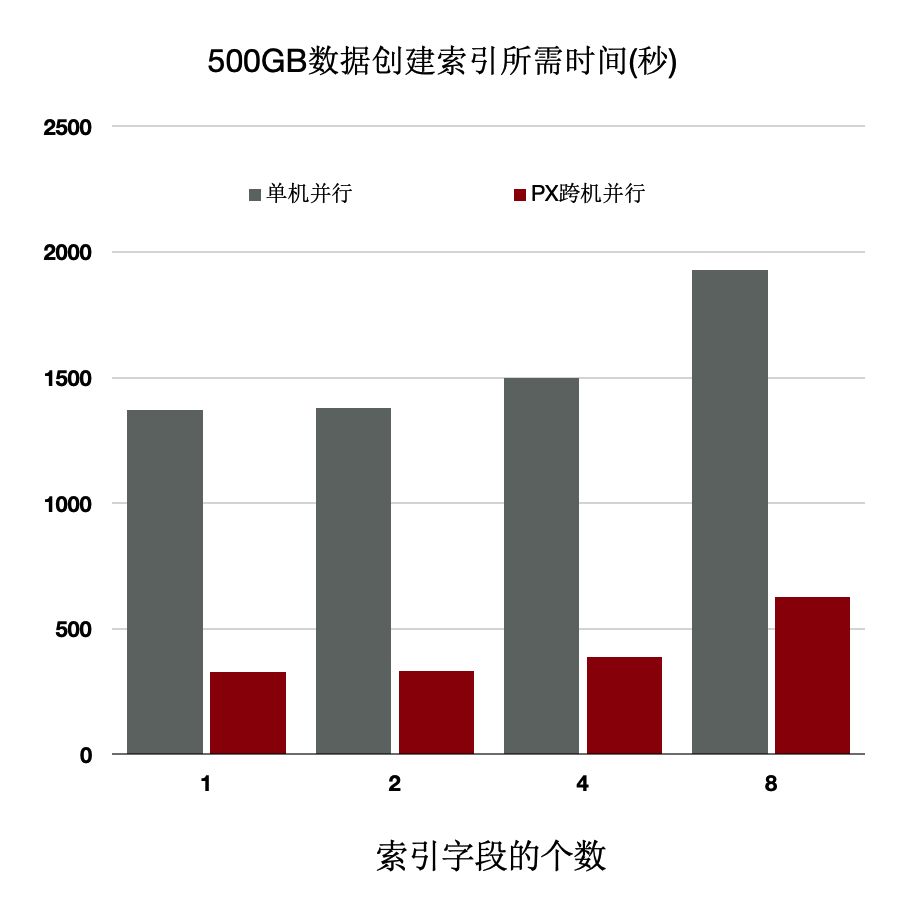
分散式並行執行加速多模 - 時空資料庫
PolarDB是對多模資料庫,支援時空資料。時空資料庫是計算密集型和IO密集型,可以藉助分散式執行來加速。我們針對共享儲存開發了掃描共享RTREE索引的功能。
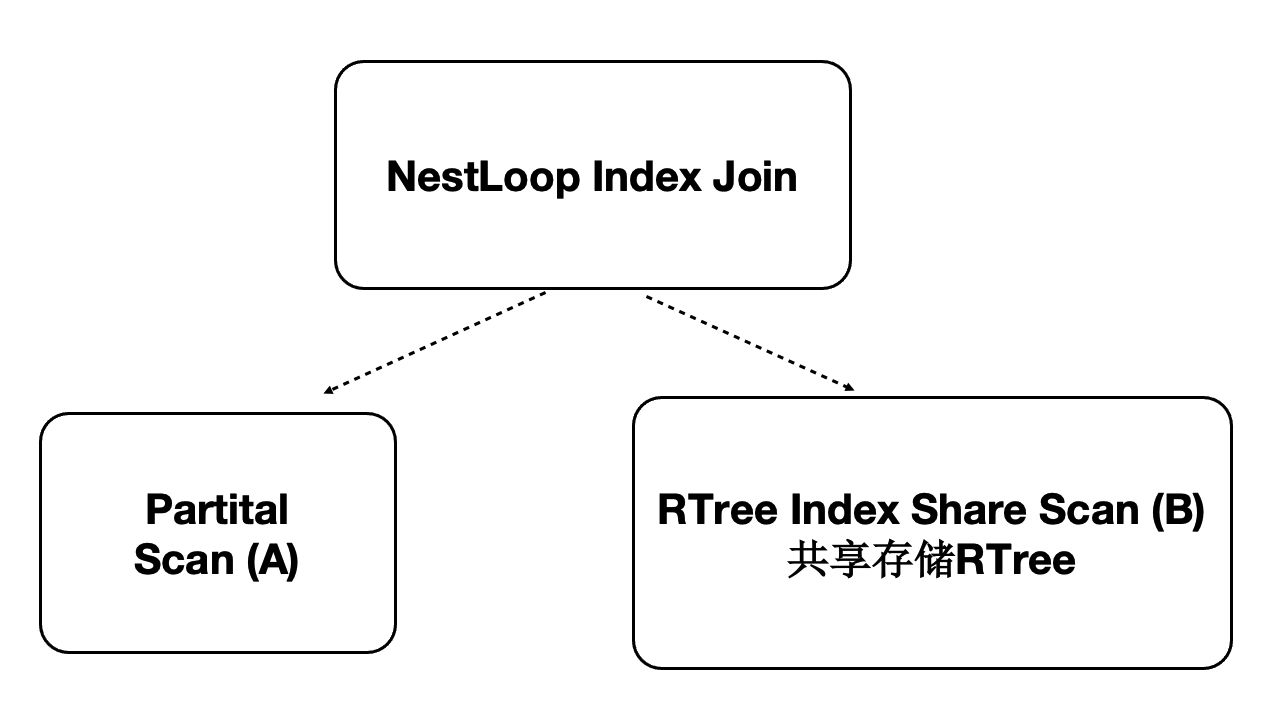
- 資料量:40000萬,500 GB
- 規格:5個只讀節點,每個節點規格為16 核CPU、128 GB 記憶體
- 效能:
- 隨CPU數目線性提升
- 共80核CPU時,提升71倍

總結
本文從架構層面分析了PolarDB的技術要點:
- 儲存計算分離架構。
- HTAP架構。
後續文章將具體討論更多的技術細節,比如:如何基於Shared-Storage的查詢優化器,LogIndex如何做到高效能,如何閃回到任意時間點,如何在Shared-Storage上支援MPP,如何和X-Paxos結合構建高可用等等,敬請期待。
企業級分散式開源資料庫 PolarDB for PostgreSQL-阿里雲開發者社群