
判別式模型 vs. 生成式模型
1. 簡介
生成式模型(generative model)會對\(x\)和\(y\)的聯合分佈\(p(x,y)\)進行建模,然後通過貝葉斯公式來求得\(p(y|x)\), 最後選取使得\(p(y|x)\)最大的\(y_i\). 具體地, \(y_{*}=arg \max_{y_i}p(y_i|x)=arg \max_{y_i}\frac{p(x|y_i)p(y_i)}{p(x)}=arg \max_{y_i}p(x|y_i)p(y_i)=arg \max_{y_i}p(x,y_i)\).
判別式模型(discriminative model)則會直接對\(p(y|x)\)進行建模.
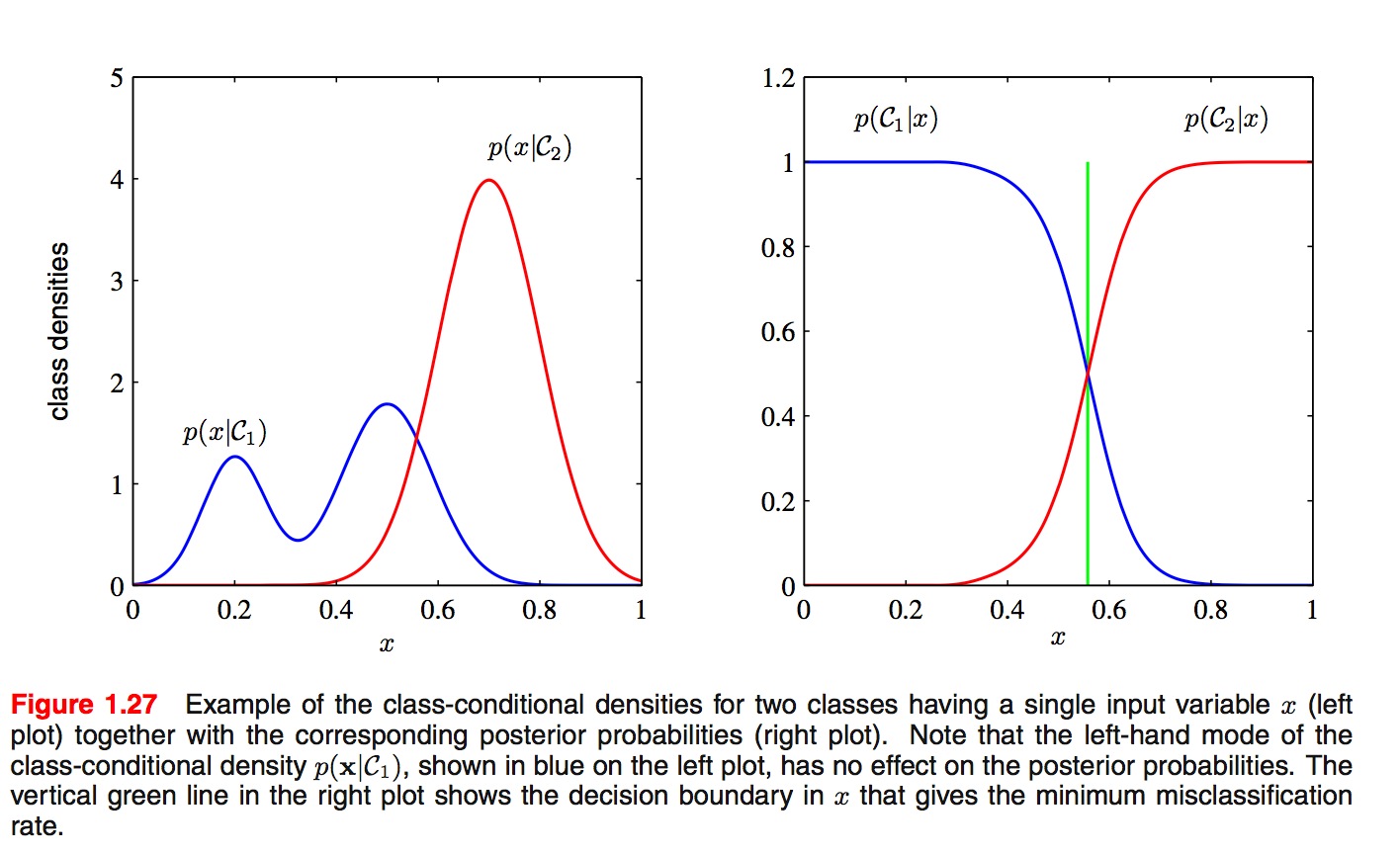
關於二者之間的優劣有大量的討論. SVM的發明者Vapnik聲稱"one should solve the (classification) problem directly and never solve a more general problem as an intermediate step [such as modeling p(x|y)]", 但是, 最近Deep Learning大行其道, 其代表性演算法DBN就是生成式模型. 通常來說, 因為生成式模型要對類條件密度(class conditional density)\(p(x|y_i)\)進行建模, 而判別式模型只需要對類後驗密度(class-posterior density)進行建模, 前者通常會比後者要複雜, 更難以建模, 如下圖所示.
2. 對比
下面簡單比較下生成式模型和判別式模型的優缺點.
1. 一般來說, 生成式模型都會對資料的分佈做一定的假設, 比如樸素貝葉斯會假設在給定\(y\)的情況下各個特徵之間是條件獨立的:\(p(X|y)=\prod_{i=1}^{N}p(x_i|y)\), GDA會假設
\(p(X|y=c,\theta)=\mathcal{N}(\mu_c,\Sigma_c)\). 當資料滿足這些假設時, 生成式模型通常需要較少的資料就能取得不錯的效果, 但是當這些假設不成立時, 判別式模型會得到更好的效果.
2. 生成式模型最終得到的錯誤率會比判別式模型高, 但是其需要更少的訓練樣本就可以使錯誤率收斂[限於Genarative-Discriminative Pair, 詳見[2]].
3. 生成式模型更容易擬合, 比如在樸素貝葉斯中只需要計下數就可以, 而判別式模型通常都需要解決凸優化問題.
4. 當新增新的類別時, 生成式模型不需要全部重新訓練, 只需要計算新的類別\(y_new\)和\(x\)的聯合分佈\(p(y_new,x)\)即可, 而判別式模型則需要全部重新訓練.
5. 生成式模型可以更好地利用無標籤資料(比如DBN), 而判別式模型不可以.
6. 生成式模型可以生成\(x\), 因為判別式模型是對\(p(x,y)\)進行建模, 這點在DBN的CD演算法中中也有體現, 而判別式模型不可以生成\(x\).
7. 判別式模型可以對輸入資料\(x\)進行預處理, 使用\(\phi(x)\)來代替\(x\), 如下圖所示, 而生成式模型不是很方便進行替換.

左圖中直接使用\(x\)進行邏輯斯蒂迴歸, 而右圖則使用徑向基核對\(x\)進行變換後再使用邏輯斯蒂迴歸.
3. 二者所包含的演算法
3.1 生成式模型
- 判別式分析
- 樸素貝葉斯
- K近鄰(KNN)
- 混合高斯模型
- 隱馬爾科夫模型(HMM)
- 貝葉斯網路
- Sigmoid Belief Networks
- 馬爾科夫隨機場(Markov Random Fields)
- 深度信念網路(DBN)
3.2 判別式模型
- 線性迴歸(Linear Regression)
- 邏輯斯蒂迴歸(Logistic Regression)
- 神經網路(NN)
- 支援向量機(SVM)
- 高斯過程(Gaussian Process)
- 條件隨機場(CRF)
- CART(Classification and Regression Tree)
參考文獻:
[1]. Kevin P. Murphy. Machine Learning: A Probabilistic Perspective, Chapter 8.6, Page267-271.
[2]. Andrew Y. Ng, Micheal I. Jordan. On Discrimintive vs. Generative Classifiers: A comparison of logistic regression and naive Bayes.
相關推薦
判別式模型 vs. 生成式模型
1. 簡介 生成式模型(generative model)會對\(x\)和\(y\)的聯合分佈\(p(x,y)\)進行建模,然後通過貝葉斯公式來求得\(p(y|x)\), 最後選取使得\(p(y|x)\)最大的\(y_i\). 具體地, \(y_{*}=arg \max_{y_i}p(y_i|x)=ar
機器學習之判別式模型和生成式模型
https://www.cnblogs.com/nolonely/p/6435213.html 判別式模型(Discriminative Model)是直接對條件概率p(y|x;θ)建模。常見的判別式模型有線性迴歸模型、線性判別分析、支援向量機SVM、神經網路、boosting
BAT面試題9:談談判別式模型和生成式模型?
BAT面試題9:談談判別式模型和生成式模型? https://mp.weixin.qq.com/s/X7zWJCMN7gbCwqskIIpLcw 判別方法:由資料直接學習決策函式 Y = f(X),或者由條件分佈概率 P(Y|X)作為預測模型,即判別模型。 生成
機器學習--判別式模型與生成式模型
一、引言 本材料參考Andrew Ng大神的機器學習課程 http://cs229.stanford.edu 在上一篇有監督學習迴歸模型中,我們利用訓練集直接對條件概率p(y|x;θ)建模,例如logistic迴歸就利用hθ(x) = g(θTx)對p(y|x;θ)建模(其中g(z)是sigmoi
什麼是判別式模型和生成式模型
判別式模型(Discriminative Model):直接對條件概率p(y|x)進行建模,常見判別模型有:線性迴歸、決策樹、支援向量機SVM、k近鄰、神經網路等;生成式模型(Generative Model):對聯合分佈概率p(x,y)進行建模,常見生成式模型有:隱馬爾可夫
判別式模型與生成式模型(二)
一、引言 本材料參考Andrew Ng大神的機器學習課程 http://cs229.stanford.edu 在上一篇有監督學習迴歸模型中,我們利用訓練集直接對條件概率p(y|x;θ)建模,例如logistic迴歸就利用hθ(x) = g(θTx)對p(y|x;θ)建模(其中g(z)是sigmoid
生成式模型(generative) vs 判別式模型(discriminative)
Andrew Ng, On Discriminative vs. Generative classifiers: A comparison of logistic regression and n
機器學習_生成式模型與判別式模型
從概率分佈的角度看待模型。 給個例子感覺一下: 如果我想知道一個人A說的是哪個國家的語言,我應該怎麼辦呢? 生成式模型 我把每個國家的語言都學一遍,這樣我就能很容易知道A說的是哪國語言,並且C、D說的是哪國的我也可以知道,進一步我還能自己講不同國家語言。
判別式與生成式模型的區別
判別式模型與生成式模型的區別 產生式模型(Generative Model)與判別式模型(Discrimitive Model)是分類器常遇到的概念,它們的區別在於: 對於輸入x,類別標籤y: 產生式模型估計它們的聯合概率分佈P(x,y) 判別式模型估計條件概率分佈P(y|x) 產生式模型可以根據貝葉
機器學習小問題 -- 生成式模型與判別式模型
本篇博文總結最近學習到的生成式模型與判別式模型的知識。 1. 簡介 就像之前在總結分類和聚類時說的一樣,機器學習基本在做的事情就是在分類、打標籤,我們的模型也就像一個個分類機器(個人看法,歡迎指正)。而這麼多的模型,可以分為兩類:生成式模型與判別式模型。 對於一個分類器
常見生成式模型與判別式模型
col 情況 玻爾茲曼機 ron location 表示 受限玻爾茲曼機 貝葉斯 馬爾科夫 生成式模型 P(X,Y)對聯合概率進行建模,從統計的角度表示數據的分布情況,刻畫數據是如何生成的,收斂速度快。 • 1. 判別式分析 • 2. 樸素貝葉斯Nati
機器學習中的概率模型和概率密度估計方法及VAE生成式模型詳解之二(作者簡介)
AR aca rtu href beijing cert school start ica Brief Introduction of the AuthorChief Architect at 2Wave Technology Inc. (a startup company
機器學習中的概率模型和概率密度估計方法及VAE生成式模型詳解之一(簡介)
價值 新書 The aar 生成 syn TE keras 第一章 A Gentle Introduction to Probabilistic Modeling and Density Estimation in Machine LearningAndA Detailed
機器學習中的概率模型和概率密度估計方法及VAE生成式模型詳解之五(第3章 之 EM算法)
ado vpd dea bee OS deb -o blog Oz 機器學習中的概率模型和概率密度估計方法及VAE生成式模型詳解之五(第3章 之 EM算法)
機器學習中的概率模型和概率密度估計方法及VAE生成式模型詳解之六(第3章 之 VI/VB算法)
dac term http 51cto -s mage 18C watermark BE ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
機器學習中的概率模型和概率密度估計方法及VAE生成式模型詳解之七(第4章 之 梯度估算)
.com 概率 roc 生成 詳解 time 學習 style BE ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?機器學習中的概率模型和概率密度估計方法及V
機器學習中的概率模型和概率密度估計方法及VAE生成式模型詳解之八(第4章 之 AEVB和VAE)
RM mes 9.png size mar evb DC 機器 DG ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
機器學習中的概率模型和概率密度估計方法及VAE生成式模型詳解之九(第5章 總結)
ces mark TP 生成 機器 分享 png ffffff images ? ?機器學習中的概率模型和概率密度估計方法及VAE生成式模型詳解之九(第5章 總結)
【機器學習】判別模型vs生成模型
判別模型vs生成模型 條件概率分佈p(y|x) 從概率的角度來看監督學習的話,其實就是從資料集中學習條件概率分佈p(y|x)。其中,x∈Rn表示n維資料特徵,y∈R表示資料對應的類別標籤。給定一個x,模型計算出x屬於各個類別標籤y的概率p(y|x),然後
判別模型 vs 生成模型
判別式模型舉例:要確定一個羊是山羊還是綿羊,用判別模型的方法是從歷史資料中學習到模型,然後通過提取這隻羊的特徵來預測出這隻羊是山羊的概率,是綿羊的概率。生成式模型舉例:利用生成模型是根據山羊的特徵首先學習出一個山羊的模型,然後根據綿羊的特徵學習出一個綿羊的模型,然後從這隻羊中提取特徵,放到山羊模型中看概率是多