
從字首樹談到字尾樹
前一陣看的資料結構比較多,剛好放假沒事,把一些我認為重要的寫成部落格記錄下來。
今天主要看的是樹中的兩個比較重要的資料結構
字首樹和字尾樹
這兩個樹的應用特別廣,但是我認為常看課外技術書籍的,部落格的都知道,但是一些專注於課本的同學可能就沒聽說過了。比如我們的課本 - -。
開始吧 ^_^
先說下字首字尾的概念吧。
比如單詞apple。app和appl是單詞的字首,ple和pple是單詞的字尾,字首必須從開頭字元起,結尾不定,字尾必須以末尾字元結尾,起點不限制。
一.字首樹
簡述:又名單詞查詢樹,tries樹,一種多路樹形結構,常用來操作字串(但不限於字串),和hash效率有一拼(二者效率高低是相對的,後面比較)。
性質:不同字串的相同字首只儲存一份。
操作:查詢,插入,刪除。
舉個例子:
假設有這麼幾個單詞

(1)
把它存入一棵字首樹後
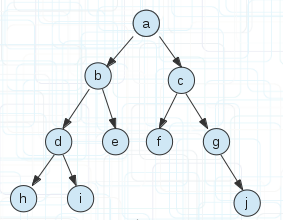
(2)
給出的單詞都是a字母開頭的,所以儲存時他們可以共用開頭字母a,接下來b字母有3個,所以它們可以共用一個字母b。
也就是說相同的字首每個字母可以共用一個空間,我有1000個a開頭的字母,那麼它們也只需要一個空間a即可。
比如上圖abdh和abdi這兩個,也只有h和i不用而已。
從(1)(2)圖片我們可以看出字首樹相對來說是非常節省空間的,比如上面兩個圖片,(1)用陣列儲存18個空間,(2)只用了10個空間。(資料量大會忽略指標域所佔空間的)。
除了節省空間外它的查詢效率也是非常高的,只需要O(logL), L是單詞的長度。一般來說我們的單詞長度都不會太長吧,就那常見的來說也就20or30?
1.查詢操作:
上面的圖片只是簡單的例子,如果我們用陣列來實現的話,樹根應該是一個空節點,它有指標域指向單詞的所有開頭字母也就是a-z。
按照字串的每個字元來比較,比如abdi,a符合,然後比較第二個字母是b,繼續比較直到末尾...
查詢操作還是很簡單的。
有個疑問就是上面圖片中有abdh這個單詞,我們怎麼知道有沒有abd或者ab這個單詞呢,畢竟它也在這棵字首樹中。
簡單,我們只需要給每個節點增加一個引用計數即可,比如有1000個a開頭的字母,那麼a的應用計數就是1000,ab開頭的有999個,那麼b的引用計數就是999,
可見b的引用計數小於a,所以存在單詞a,那麼得出結論:
某個字串在字首樹中的結尾字母的引用計數如果大於末節點的下一個節點的引用計數(大1),說明存在此單詞。
2.插入操作:
依次比較經過的每一個字母,如果字母存在,則給字母的引用計數加1,如果該字母不存在,直接從該字母開始到此字串的末尾的每一個字母
連線到這棵字首樹上。
3.刪除操作:
依次比較經過的每一個字母,給所經過的每個字母的引用計數值減1,如果該引用計數值為0的話,則刪除此節點,此節點往後的節點也刪除,
因為必定都屬於這個單詞。
4.重點:字首樹的應用
字首樹還是很好理解,但是它的應用是非常廣的。
<1.字串的快速檢索
前面也說了字典樹的查詢時間複雜度是O(logL),L是字串的長度。所以效率還是比較高的。
前面說了字典樹的效率和hash表有一拼,這裡來分析下,網上的一部分文章說的都是字典樹的效率比hash表高。我覺得還是相對來看比較好,各有個的特點吧。
hash表,通過hash函式把所有的單詞分別hash成key值,查詢的時候直接通過hash函式即可,都知道hash表的效率是非常高的為O(1),直接說字典樹的查詢效
率比hash高,難道有比O(1)還快的- -。
hash:
當然對於單詞查詢,如果我們hash函式選取的好,計算量少,且衝突少,那單詞查詢速度肯定是非常快的。那如果hash函式的計算量相對大呢,且衝突律高呢?
這些都是要考慮的因素。且hash表不支援動態查詢,什麼叫動態查詢,當我們要查詢單詞apple時,hash表必須等待使用者把單詞apple輸入完畢才能hash查詢。
當你輸入到appl時肯定不可能hash吧。
字典樹(tries樹):
對於單詞查詢這種,還是用字典樹比較好,但也是有前提的,空間大小允許,字典樹的空間相比較hash還是比較浪費的,畢竟hash可以用bit陣列。
那麼在空間要求不那麼嚴格的情況下,字典樹的效率不一定比hash若,它支援動態查詢,比如apple,當用戶輸入到appl時,字典樹此刻的查詢位置可以就到達l這個
位置,那麼我在輸入e時光查詢e就可以了(更何況如果我們直接用字母的ASCII作下標肯定會更快)!字典樹它並不用等待你完全輸入完畢後才查詢。
所以效率來講我認為是相對的。
<2.字串排序
從上圖(2)我們很容易看出單詞是排序的,先遍歷字母序在前面的比如abdh,然後abdi。
減少了沒必要的strcmp
這個很好理解。
<3.最長公共字首
abdh和abdi的最長公共字首是abd,遍歷字典樹到字母d時,此時這些單詞的公共字首是abd。
<4.自動匹配字首顯示字尾
我們使用辭典或者是搜尋引擎的時候,輸入appl,後面會自動顯示一堆字首是appl的東東吧。
那麼有可能是通過字典樹實現的,前面也說了字典樹可以找到公共字首,我們只需要把剩餘的字尾遍歷顯示出來即可。^_^
二.字尾樹
簡介:字尾樹,就是把一串字元的所有後綴儲存並且壓縮的字典樹。相對於字典樹來說,字尾樹並不是針對大量字串的,而是針對一個或幾個字串來解決問題,
比如字串的迴文子串,兩個字串的最長公共子串等等,後面應用會說。
性質:一個字串構造了一棵樹,樹中儲存了該字串所有的字尾。
操作:就是建立和應用。
1.建立字尾樹
比如單詞banana,它的所有後綴顯示到下面的。1代表從第一個字元為起點,終點不用說都是字串的末尾。

以上面的字尾,我們建立一顆字尾樹。如下圖,為了方便看到字尾,我沒有合併相同的字首
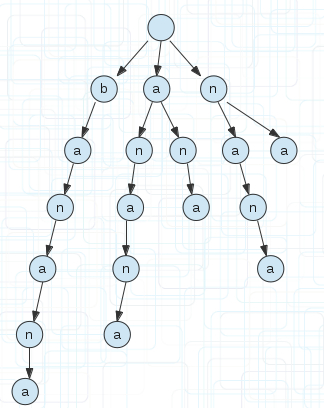
(3)
前面簡介的時候我們說了,字尾樹是把一個字串所有後綴壓縮並儲存的字典樹。
壓縮一會再說,簡介裡面說了是字典樹,所以我們把字串的所有後綴還是按照字典樹的規則建立,就成了上圖(3)的樣子。
注意還是和字典樹一樣,根節點必須為空。
下面說下更加節省空間的方案,也就是上面提到的壓縮。
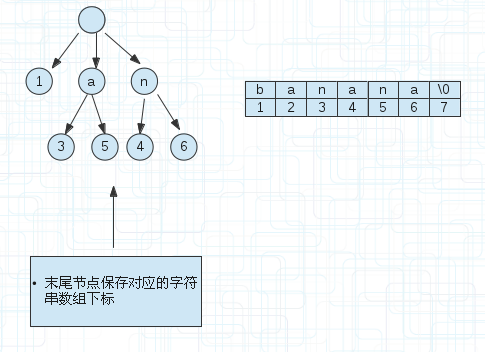
(4)
因為有些字尾串可能是單串,並不和其他的共用同一個字首。
比如圖(4)的banana這個字尾串,直接可以用1來表示起點,終點是預設的。
圖(4)的a節點後面有兩個節點標記3和5是右邊字元陣列的下標,對應著a->3-7,a->5-7。因為a是共有的字首。
2.重點說下字尾樹的應用,它能解決大多數字符串的問題
<1.查詢某個字串s1是否在另外一個字串s2中
這個很簡單,如果s1在字串s2中,那麼s1必定是s2中某個字尾串的字首。
理解以下字尾串的字首這個詞,其實每個字尾串也就是起始地點不同而已,字首也就是從開頭開始結尾不定。
字尾串的字首就可以組合成該原先字串的任意子串了。
比如banana,anan是anana這個字尾串的字首。
<2.指定字串s1在字串s2中重複的次數
看圖(3),比如說banana是s1,an是s2,那麼計算an出現的次數實際上就是看an是幾個字尾串的字首。
上圖的a節點是儲存所有起始為a字母的字尾串,我們看a字母后的n字母的引用計數即可。
先說下廣義字尾樹,前面說了字尾樹可以儲存一個或多個字串,當儲存的字串數量大於等於2時就叫做廣義字尾樹。
<3.兩個字串S1,S2的最長公共部分(廣義字尾樹)建立一棵廣義字尾樹,如下圖(5)
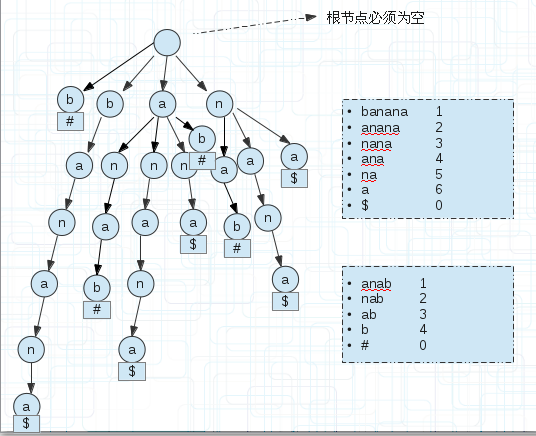
(5)
$和#是為了區分字串的。
我們為每個字尾串末尾單獨新增一個空間儲存區分字串的符號。
那麼怎麼找s1和s2串最長的公共部分?
遍歷每個字尾串,如果其引用計數為1則直接跳過,因為不可能有兩個子串存放在這裡,當引用計數>1時,往下遍歷,直到分叉分別記錄子串的符號,
如果不同,說明他們是不同字串的,記錄已經匹配的值即可,若相同繼續下一次遍歷。
上圖的ana部分,到ana時,子串$結束,然後繼續向下,子串anab以#結束,那麼匹配了ana。
<4.最長迴文串(廣義字尾樹)
把要求的最長迴文串的字串s1和它的反向(逆)字串s2建立一棵廣義字尾樹。
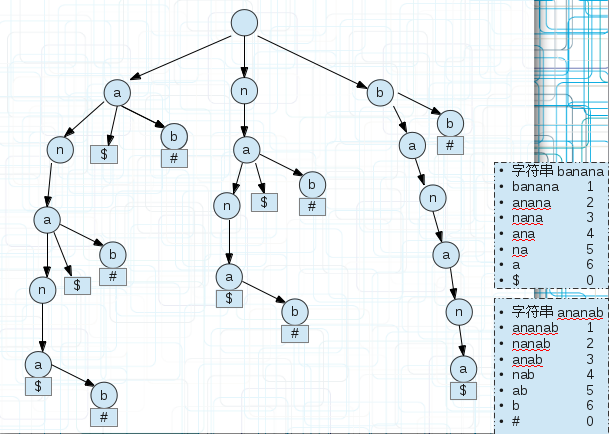
迴文串有一個定義就是正反相同,也就是正著和反著可以重和在一起,那麼我們直接看這棵廣義字尾樹的共同字首即可,每個banana的子串和ananab的子串重合的部分
都是迴文串,我們只需要找到最長的即可。比如上面的anana,從後面不同的標記可以看出兩個字串的某個字尾都有這個字首,能完美重合到一起。即它是迴文串。
記錄Max,每次找到一個迴文串比較即可。