
OCR----Tesseract 3.x架構及原理解析
Tesseract的歷史
Tesseract是一個開源的OCR引擎,惠普公司的布裡斯托爾實驗室在1984-1994年開發完成。起初作為惠普的平板掃描器的文字識別引擎。Tesseract在1995年UNLV OCR字元識別準確性測試中拔得頭籌,受到廣泛關注。後來HP放棄了OCR市場。在1994年以後,Tesseract的開發就停止了。
在2005年,HP將Tesseract貢獻給開源社群。美國內華達州資訊科技研究所獲得該原始碼,同時,Google開始對Tesseract進行功能擴充套件及優化。目前,Tesseract作為開源專案釋出在Google Project上,重獲新生。Tesseract的最新版本是3.02,它支援60種以上的語言,提供一個引擎和一個命令列工具,官方下載地址:
Tesseract架構解析
Tesseract引擎功能強大,概括地可以分為兩部分:
- 圖片佈局分析
- 字元分割和識別
圖片佈局分析,是字元識別的準備工作。工作內容:通過一種混合的基於製表位檢測的頁面佈局分析方法,將影象的表格、文字、圖片等內容進行區分。
字元分割和識別是整個Tesseract的設計目標,工作內容最為複雜。首先是字元切割,Tesseract採用兩步走戰略:
- 利用字元間的間隔進行粗略的切分,得到大部分的字元,同時也有粘連字元或者錯誤切分的字元。這裡會進行第一次字元識別,通過字元區域型別判定,根據判定結果對比字元庫識別字符。
- 根據識別出來的字元,進行粘連字元的分割,同時把錯誤分割的字符合並,完成字元的精細切分。
- 分析連通區域
- 找到塊區域
- 找文字行和單詞
- 得出(識別)文字
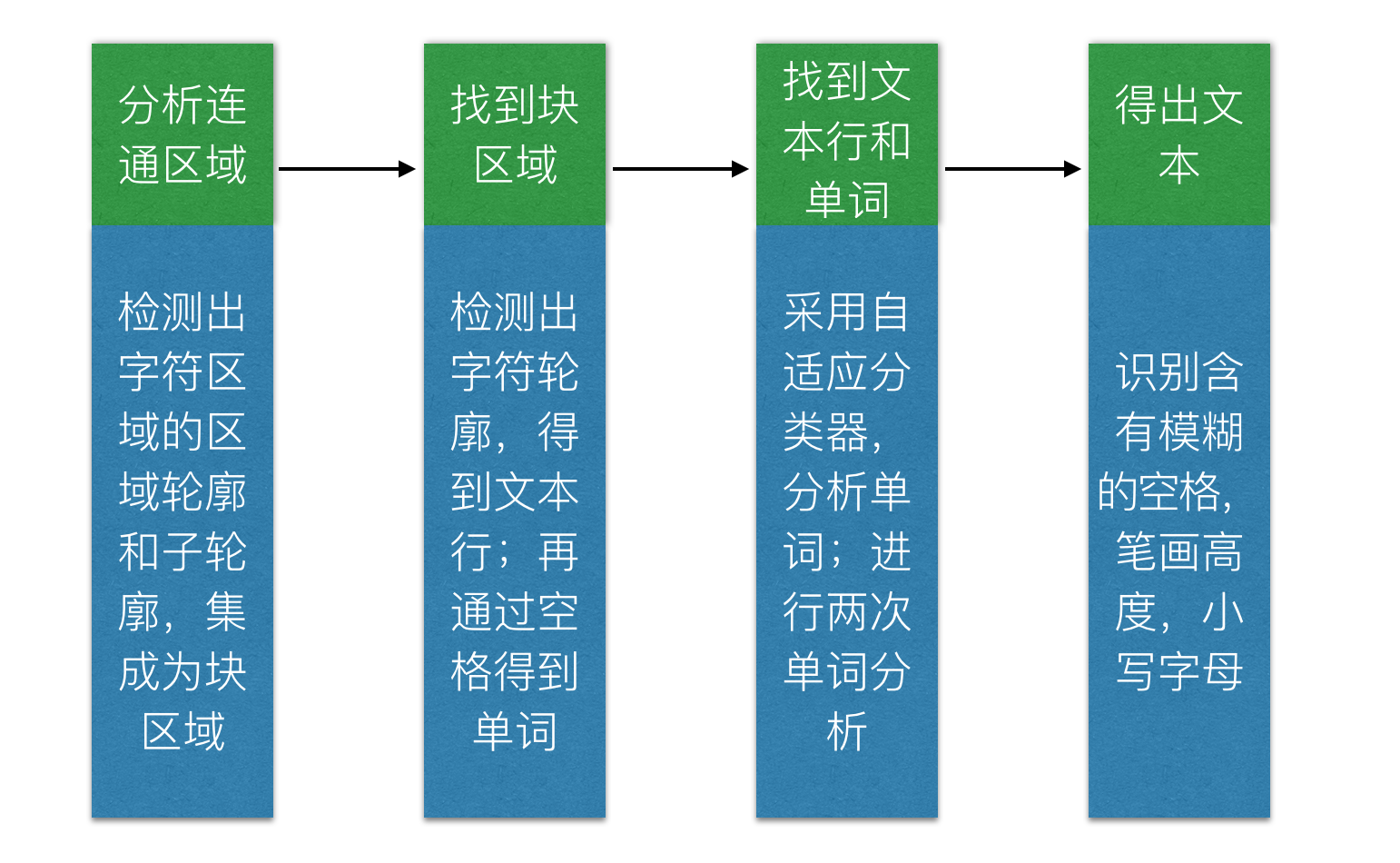
不想貼文字,直接上圖:
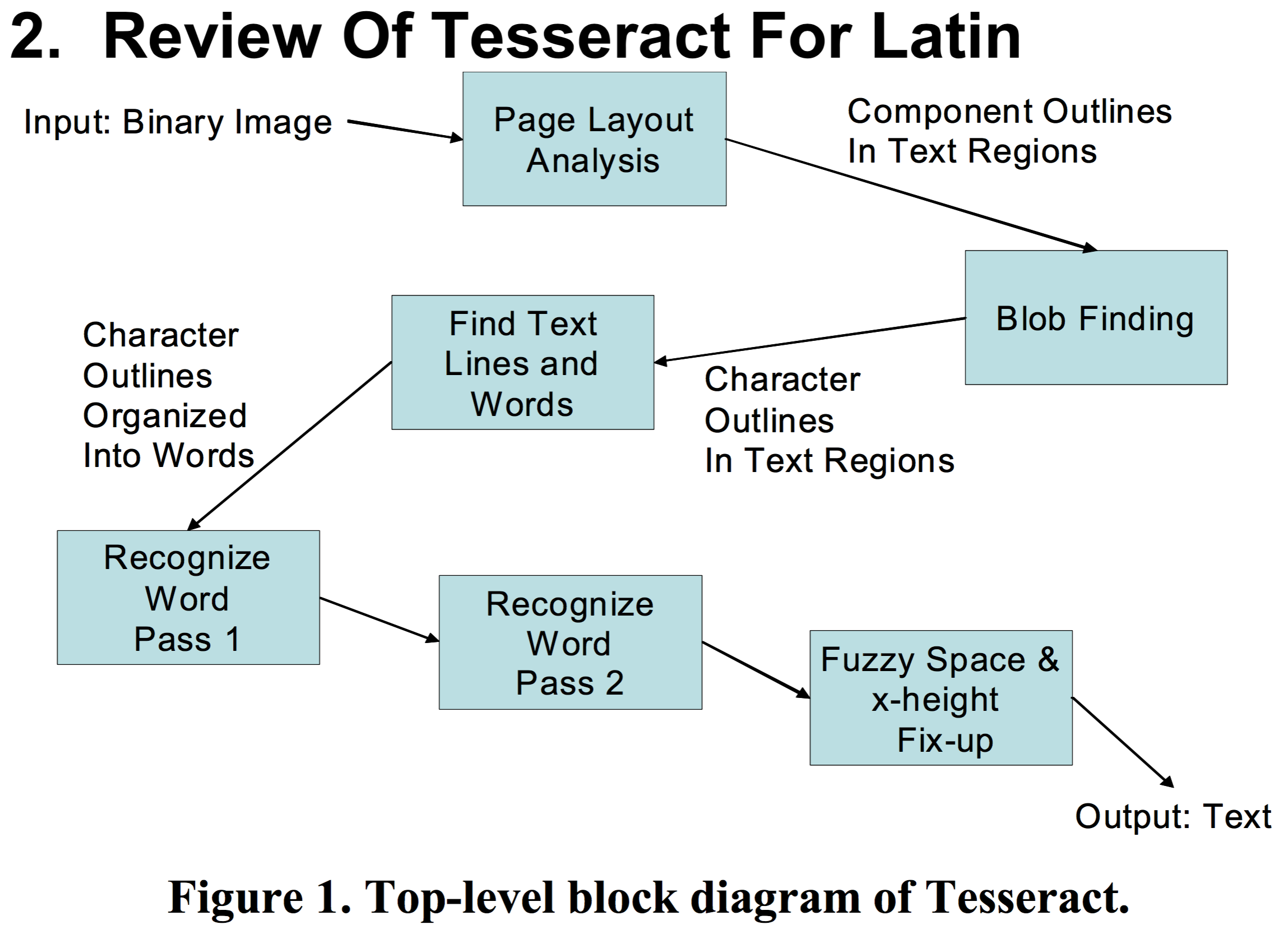
Tesseract的架構並不是我這三言兩語能講清楚地,歡迎留言補充糾正!謝謝合作!
Tesseract實現原理
原理這塊相當複雜,這篇blog只談TessBaseAPI相關的東西。後續系列再撰文補充。
TessBaseAPI是Tesseract引擎的一個核心類,關於這個類的原始碼請戳這裡:谷震平的傳送門。我們來理解下這個類函式的運作機制,藉此聯想下Tesseract引擎的實現原理。機制如下:
- 呼叫Init()方法,即對引擎初始化
- 呼叫setImage()方法,設定圖形流的資訊
- 通過getUTF8Text()方法獲得text資訊
- 呼叫recognizedText類,判斷text的正確性,然後輸出。這裡,會呼叫自有的trim()方法和length()方法做一些相應的處理。
關於Init()方法,官方的API介紹:
Instances are now mostly thread-safe and totally independent, but some global parameters >remain. Basically it is safe to use multiple TessBaseAPIs in different threads in parallel, UNLESS: you use SetVariable on some of the Params in classify and textord. If you do, then the effect will be to change it for all your instances.
Start tesseract. Returns zero on success and -1 on failure. NOTE that the only members that may be called before Init are those listed above here in the class definition.
The datapath must be the name of the parent directory of tessdata and must end in / . Any name after the last / will be stripped. The language is (usually) an ISO 639-3 string or NULL will default to eng. It is entirely safe (and eventually will be efficient too) to call Init multiple times on the same instance to change language, or just to reset the classifier. The language may be a string of the form [~][+[~]]* indicating that multiple languages are to be loaded. Eg hin+eng will load Hindi and English. Languages may specify internally that they want to be loaded with one or more other languages, so the ~ sign is available to override that. Eg if hin were set to load eng by default, then hin+~eng would force loading only hin. The number of loaded languages is limited only by memory, with the caveat that loading additional languages will impact both speed and accuracy, as there is more work to do to decide on the applicable language, and there is more chance of hallucinating incorrect words. WARNING: On changing languages, all Tesseract parameters are reset back to their default values. (Which may vary between languages.) If you have a rare need to set a Variable that controls initialization for a second call to Init you should explicitly call End() and then use SetVariable before Init. This is only a very rare use case, since there are very few uses that require any parameters to be set before Init.
If set_only_non_debug_params is true, only params that do not contain “debug” in the name will be set.
The datapath must be the name of the data directory (no ending /) or some other file in which the data directory resides (for instance argv[0].) The language is (usually) an ISO 639-3 string or NULL will default to eng. If numeric_mode is true, then only digits and Roman numerals will be returned.
- Returns
- 0 on success and -1 on initialization failure.
其他函式的介紹,自己去讀一些API吧,我就不貼了。API傳送門
圖 TessBaseAPI內建的一些方法
The End
我覺得自己肯定沒有寫清楚,歡迎留言來批評!
特別希望黨老師來批評!
謝謝大家!
內容來自谷震平的blog,尊重原創,轉載請註明出處!
謝謝~