
基於句子相似度的FAQ問答系統
總結一波我的專案之一,歷史久遠,要把它理清一下。
Introduce:日趨增多的網路資訊使使用者很難迅速從搜尋引擎返回的大量資訊中找到所需內容。自動問答系統為人們提供了以自然語言提問的交流方式,為使用者直接返回所需的答案而不是相關的網頁,具有方便、快捷、高效等特點。
Process:本文的問答系統採用了一個FAQ(Frequently Asked Questions)問答庫,並基於句子相似度進行設計。
1)首先建立一個足夠大的問題答案庫,即語料庫--------建庫
2)然後計算使用者提問的問題和語料庫中各個問題的相似度-------計算相似度-------餘弦定理
3)最後把相似度較高的問題所對應的答案返回給使用者。-------返回結果
core: 本文的核心是句子相似度的計算,分別使用了TF-IDF和word2vec兩種方法對問句進行向量化,並在此基礎上使用進行句子相似度的計算。
Improve:為了提高整個系統的執行速度,本文對演算法的計算進行了相應的優化。
key words:FAQ;句子相似度;TF-IDF;word2vec;餘弦定理
part1: research background and meaning
基於常問問題集的問答系統是在已有的問題答案對的集合中找到與使用者提問相匹配的問題,並將其對應的答案直接返回給使用者。
問答系統是目前自然語言處理領域的一個研究熱點
優點:1)讓使用者用自然語言句子提問
2)為使用者返回一個簡潔、準確的答案,而不是一些相關的網頁。
與傳統的依靠關鍵字匹配的搜尋引擎相比,能夠更好地滿足使用者的檢索需求,更準確地找出使用者所需的答案,具有方便、快捷、高效等特點。如果使用者的提問與以往的記錄相符,可直接將對應的答案提交給使用者,免去了重新組織答案的過程,可以提高系統的效率。
常問問題集(FAQ)可以作為自動問答系統中的一個組成部分。它把使用者經常提問的問題和相關答案儲存起來。對於使用者輸入的問題,可以首先在常問問題庫中查詢答案。
如果能夠找到相應的問題,就可以直接將問題所對應的答案返回給使用者,而不需要經過問題理解、資訊檢索、答案抽取等許多複雜的處理過程,提高了效率。我們提出的FAQ(Frequently Asked Questions)系統在根據使用者問題建立候選問題集的基礎上,建立常問問題集的倒排索引,提高了系統的檢索效率,同時,與傳統的基於關鍵詞的方法相比,用基於語義的方法計算相似度提高了問題的匹配精度。
part 2: FAQ Answering System
2.1 Introduction to FAQ Answering System
問答式檢索系統允許使用者用自然語言提問,從大量異構資料中準確而快速查找出提問的答案,是集自然語言處理技術和資訊檢索技術與一體的新一代搜尋引擎。這種提供準確、簡潔的資訊的方式更接近於人的思維和習慣,是下一代搜尋引擎的發展方向。
FAQ問答系統是一種已有的“問題-答案”對集合中找到與使用者提問相匹配的問句,並將其對應的答案返回給使用者的問答式檢索系統。由於FAQ問答系統免去了重新組織答案的過程,可以提高系統的效率,還可以提高答案的準確性。這其中要解決的一個關鍵問題是使用者問句與“問題-答案”對集合中問句的相似度比較,並把最佳結果返回給使用者。
2.2 The "Questions - Answers" Library
FAQ問答系統需要一個“問題-答案”庫的支撐,庫的好壞直接影響問答系統的效果。本設計所用的“問題-答案”庫來源於百度知道的問題和對應的答案,共有10000條。使用者輸入問題,然後從庫中匹配相似度符合設計閾值的問題並顯示其答案。

部分問題

部分答案
3 System Design and Implementation
3.1 Design Principles and Flow Charts
思想:把語料庫的問題和使用者所提問題預處理,然後向量化,最後通過計算兩向量之間的餘弦夾角值作為衡量相似度的值。只有該餘弦值大於程式設定中的閾值才會將這些問題作為候選問題返回給使用者。本設計的閾值設定為0.5,同時並選擇相似度最高的前5個問題(Top5)所對應的答案返回給使用者。若沒有大於閾值的樣本,則提示使用者當前的提問沒有相似的答案。系統的設計框圖如圖3-1所示。

3.2 Pretreatment of Questions
預處理是對問句進行初步處理的過程。本文對評論文字依次進行了去空去重、切詞分詞和停用詞過濾操作。
原始網路評論會存在一些空或重複的問句,須過濾掉這些無價值且影響效率的問句。使用計算機自動地對中文文字進行詞語切分的過程稱為中文分詞(Chinese Word Segmentation),即使中文句子中的詞之間有空格標識。若要對一個句子進行分析,就需要將其切分成詞的序列,然後以詞為單位進行句子的分析,故中文分詞是中文自然語言處理中最基本的一個環節。
分詞之後需要對每個詞進行詞性標註,為接下來的停用詞過濾提供便利。停用詞(Stop Word)指通常在評論文字中出現的頻率較高,但對確定評論的情感類別沒有作用的詞。停用詞過濾指去掉評論文字中停用詞的過程。本文使用中科院的“計算所漢語詞性標記集”以及哈工大停用詞表對評論文字進行停用詞過濾。根據“計算所漢語詞性標記集”,確定出要過濾掉的詞性有:標點符號、介詞和代詞等,這些詞性的詞資訊量低,無類別區分作用。本文先對評論文字進行詞性過濾,再根據哈工大停用詞表進一步過濾。
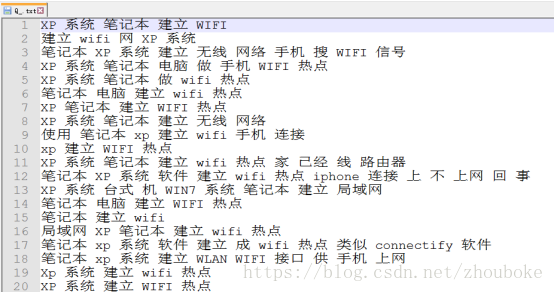
預處理後的部分問句
3.3 Text vectorization
在進行相似度計算之前,需要將每條問句都轉換成向量的形式,即將每條問句都對映到一個向量空間,分別使用了兩種方法TF-IDF(詞頻-反向文件頻率)和word2vec對問句文字進行向量化。
3.3.1 TFIDF method based on vector space model
從FAQ中所有預處理後的問句中提取特徵後,形成一個詞彙表

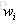
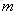
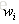
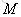
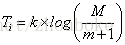
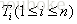
可以看出,一個問句中出現次數多的詞將被賦予較高的值,但這樣的詞並不一定具有較高的值。
eg:漢語中“的”出現的頻率非常高,TF值(k值)很大,但“的”在很多問句中都出現,它對於分辨各個問句並沒有太大的幫助,它的IDF值是一個很小的數。因此,這種方法綜合地考慮了一個詞的出現頻率和這個詞對不同問句的分辨能力。
在計算使用者提問問句的n 維向量時,使用者提問問句和FQA庫中的問句b不是同時向量化的,故在對FQA庫中的問句向量化時,需要儲存每個特徵的ID F值,便於使用者提問問句中特徵詞TFIDF值的計算。
3.3.2 word2vec word vector model
word2vec是用來產生詞向量的一組相關模型。它利用輸入的語料來產生一個向量空間,在這個向量空間中,每個詞對應一個點,語義上相近的詞在向量空間上對應的點也相近。
word2vec中兩個重要的模型:
CBOW模型(Continuous Bag-of-Words Model)和Skip-gram模型(Continuous Skip-gram Model)。
CBOW模型的思想是用上下文來預測當前詞的概率,而Skip-gram模型的思想是用當前詞來預測其上下文詞的概率。它們的目標函式分別為: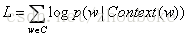
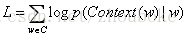
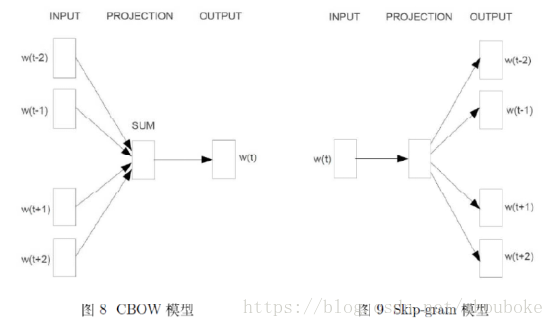
左為CBOW模型,右為Skip-gram模型
本文使用sougou大語料並基於CBOW模型訓練得到詞向量,然後使用問句中每個特徵詞對應詞向量的算術平均作為問句的句向量。
3.4Calculation of sentence similarity based on cosine theorem
問句之間的相似度可以轉換為向量之間的距離來進行度量。距離越小問句之間的相似性越大,反之亦然。
本文采用餘弦夾角來計算向量之間的相似度,相似問題一般包含更多相同的特徵詞,兩個問句的主題是否接近,取決於它們的特徵向量“長得像不像”。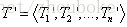
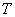
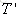
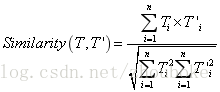
由上述公式可知,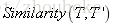
餘弦相似度的定義雖然簡單,但是在利用上述公式計算兩個向量的夾角時,計算量為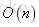
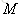
我們這個方案解答需要大概30秒的時間,這個時間對於使用者來說過於長,使用者體驗效果不佳。為了降低計算量,本文在計算相似度時進行了一些簡化:
1)首先,分母部分(即向量的模)不需要重複計算,即可以將它們進行預計算,並將預計算的結果儲存起來,等計算向量模的時候,直接取出來即可。
2)其次,分子部分,即在計算兩個向量的內積時,只需考慮向量中的非零元素,計算複雜度取決於兩個向量中非零元素個數的最小值。這兩個簡化方法在使用TF-IDF向量化時效果比較明顯,因為TF-IDF得到的向量極其高維和稀疏,而word2vec得到的向量則是低維和稠密,效果不是很明顯。
4 Experimental results and analysis
4.1 Experiment Settings
表4-1 測試問題集
|
具有相似性的問題 |
基本無相似度的問題 |
|
1.小米怎麼發彩信啊? |
1.大臉剪什麼短髮好看 |
|
2.如何成為經理? |
2.怎麼做拔絲地瓜 |
|
3.怎樣在聚划算賣東西 |
3.華為自動關機為什麼 |
|
4.怎樣停止建行卡的簡訊通知? |
4.去哪買手機比較好 |
|
5.你對知音有什麼看法 |
5.怎樣提高數學成績 |
|
6.地震你怎麼看 |
6.什麼翻譯軟體比較好 |
|
7.選哪個快遞?順豐咋樣 |
7.出國去哪裡比較好 |
|
8.湖南長沙要穿防晒服嗎 |
8.身份證掉了怎麼補辦 |
|
9.三星I910儲存量是多少 |
9.怎樣種藍庭芥 |
|
10.CAD的修剪命令怎麼操作? |
10.理八棟誰最帥 |
4.2 Experimental Results and Analysis
基於TF-IDF演算法的句子相似度計算方法基本可以回答表4-1中“具有相似性的問題”,而對於表4-1中“基本無相似度的問題”,則會提示使用者該問題基於當前的FAQ問答庫無法回答,這說明基於相似度的FAQ問答系統完全依賴於語料庫。
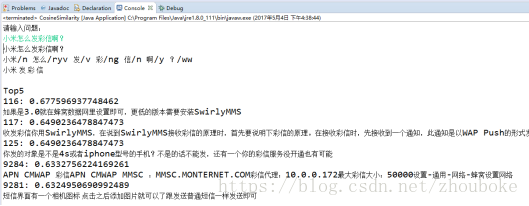
相似問題測試結果
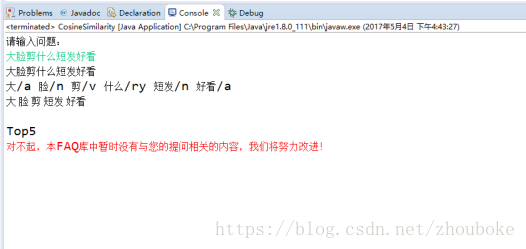
基本無相似度問題測試結果
當輸入與語料庫中問題相似的問題時,能得到較為正確的答案。
而對於與語料庫中問題基本無相似度的問題,系統則會提示使用者系統回答不了當前問題。
本文的TF-IDF演算法的問答系統設定了相應的閾值,即當用戶提問的問句與問答庫中的問句相似度大於閾值時,才輸出相應的問句所對應的答案,這裡閾值是0.5。除此之外,本文對於閾值過濾後的答案,進行排序,先出閾值最高的前5個(Top5)反饋給使用者。
基於word2vec的句子相似度計算方法,在計算速度上比基於TF-IDF的方法速度快,因為word2vec訓練出來的向量要更低維和稠密。但是由於在進行詞向量訓練的時候,使用的是sougou大語料,該語料與本文的問句沒有太大的關係,故訓練出來的詞向量不能很好的代表問答領域問句的一些語義資訊,故在最終進行測試的時候,計算出來的結果無法達到預期的效果。
5 Summary and Outlook
本文使用了兩種句子向量化演算法對句子進行向量化:即TF-IDF和word2vec。
這兩種向量化演算法都能在一定程度上刻畫出句子之間的相似度【餘弦相似度】。
對於TF-IDF演算法,其訓練出來的句子向量具有高維、稀疏的缺點,故在計算的時候比較慢,本文針對這個問題對其進行了優化,在一定程度上降低了時間複雜度。
相反,對於word2vec演算法,其訓練出來的向量具有低維、稠密的優點,計算速度快,但詞向量的訓練需要大量的語料才能達到好的效果。這次訓練語料比較不匹配,得到的向量不能很好地表示句子之間的相似性,效果較差。
由此可見,在進行word2vec詞向量的訓練時,需要根據具體的問題,使用合適的語料,這樣才能更好的表示句子之間的相似度。