
機器學習門下,有哪些在工業界應用較多,前景較好的小方向?
推薦一個尚未受到足夠重視但潛力很大的方向:異常檢測(anomaly detection),也叫異常分析(outlier analysis),相關的還有novelty detection。異常檢測在工業上有非常廣泛的應用場景:
- 金融業:從海量資料中找到“欺詐案例”,如信用卡反詐騙,識別虛假信貸
- 網路安全:從流量資料中找到“侵入者”,識別新的網路入侵模式
- 線上零售:從交易資料中發現“惡意買家”,比如惡意刷評等
- 生物基因:從生物資料中檢測“病變”或“突變”
換句話來說,異常檢測就是從茫茫資料中找到那些“長得不一樣”的資料。但檢測異常過程一般都比較複雜,而且實際情況下資料一般都沒有標籤(label),我們並不知道哪些資料是異常點,所以一般很難直接用簡單的監督學習。異常值檢測還有很多困難,如極端的類別不平衡、多樣的異常表達形式、複雜的異常原因分析等。
從人才供給上來看,專門研究或者應用異常檢測的人才是非常有限的。而且大部分人往往都更青睞於傳統網際網路科技公司,留給銀行和零售業的可用之人並不多。因此,已經身處某個行業的朋友們很適合瞭解學習異常檢測,從而彌補所屬領域對於異常檢測人才的需求。
1. 應用場景與前景
像文章開頭提到的,異常檢測的主要應用場景是風險控制(risk control),常見於金融機構、保險機構、銀行等。以我的個人體會為例,各大銀行都在擴充自己的資料分析團隊,嘗試用機器學習手段來降低如銀行卡盜刷的案例。而且值得關注的是,大部分銀行的風控手段往往都還有很大的升級空間,十月份的時候我和加拿大最大的銀行之一的機器智慧(machine intelligence)主管交流時,他告訴我他們的部門總共才7個人,最大的困難就是找不到合適的人,即缺少懂得用機器學習來做風控的又願意加入銀行的人。
換個角度來看,對於銀行和普通金融機構來說,最大的挑戰是很難吸引科技人才。大部分科技人才都還是選擇加入網際網路公司,比如國內的BAT或者國外的FLAG。
我也曾給另一個跨國保險公司做過詐騙識別的專案。他們所使用的風控軟體叫做NetReveal,花費數百萬美元,但誤差率高達百分之90。換句話說,100個識別出的欺詐中只有不到10個是真的詐騙,浪費了大量的人力物力。在引入了機器學習的異常檢測後,我們大幅度降低了誤差率。
拿銀行和保險行業的例子是為了說明這個方向缺口很大,但相關人才很少,有符合技能的人才又往往不願意委身於此。因此,異常檢測在風控中的前景非常光明,屬於為數不多機器學習能夠落地的方向。
2. 相關技術
異常檢測可以通過監督學習或者非監督學習來做,但往往最終還是需要非監督學習
退一步說,即使我們真的有詐騙的歷史資料,即在有標籤的情況下用監督學習,也存在很大的風險。用這樣的歷史資料學出的模型只能檢測曾經出現過與歷史詐騙相似的詐騙,而對於變種的詐騙和從未見過的詐騙,我們的模型將會無能為力。因此,在實際情況中,一般不建議直接用任何監督學習,至少不能單純依靠一個監督學習模型來奢求檢測到所有的詐騙。除此之外,欺詐檢測一般還面臨以下問題:
1. 九成九的情況資料是沒有標籤(label)的,各種成熟的監督學習(supervised learning)沒有用武之地。
2. 區分噪音(noise)和異常點(anomaly)時難度很大,甚至需要發揮一點點想象力和直覺。
3. 緊接著上一點,當多種詐騙資料混合在一起,區分不同的詐騙型別更難。根本原因還是因為我們並不瞭解每一種詐騙定義。
一般來看,我們把異常檢測的技術包括:
1. 建立在統計學意義上的檢測方法:
- 極值分析(extreme value analysis)。這樣的方法往往僅對單獨維度進行研究,使用上有很大的侷限性。
- 對資料分佈進行假設,如對異常資料和正常資料進行不同的分佈假設,並用EM演算法擬合數據。這樣的方法侷限性在於假設往往和實際有較大出入,效果一般。
2. 基於線性分析的檢測方法,特指在低維度上分析資料間相關性的方法。這樣的方法包括維度壓縮如PCA,Factor Analysis等。這類方法的問題在於把資料壓縮後或者找到低維嵌入後,資料的可解釋性下降,我們很難解釋為什麼異常是異常。
3. 基於時空上的異常檢測,特指異常和其所處的環境有關:
- 空間關係造成的異常:
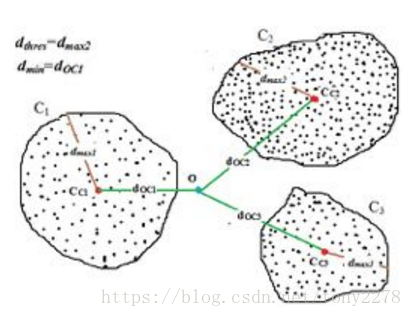
O點在單獨來看的情況下是正常點,但考慮到臨近點後就是異常點
- 時間序列上的異常:
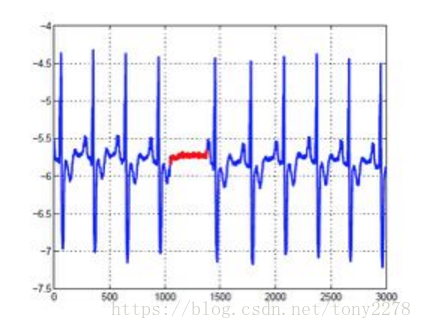
紅色部分單獨來看不是異常,但考慮到臨近點後就是異常點
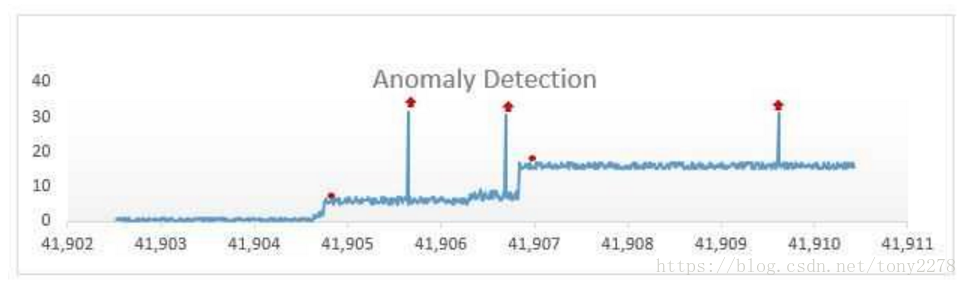
4. 建立在相似性分析上的異常檢測(proximity based outlier detection):
- 建立在距離度量的上的異常檢測(distance based),如K-近鄰為原型的也可歸為此類
- 建立在密度分析上的異常檢測,如經典的 Local outlier factor(LOF)
5. 其他各種異常檢測方法,包括:
- 整合異常檢測(outlier ensemble):代表性的演算法有isolation forest,feature bagging
- 監督異常檢測,半監督異常檢測,主動學習(active learning)
- 圖中的異常檢測,也包括網路中的異常檢測
3. 學習路徑推薦
雖然異常檢測有非常廣闊的應用場景,但據我所知還沒有一門公開課或者中文書籍系統的討論相關的問題。以英文材料為例,比較權威的是Charu Aggarwal的Outlier Analysis,本文也多處參考了這本書的內容。
我自己覺得比較恰當的學習路徑是:
- 掌握基礎的、通用的機器學習知識,如周志華《機器學習》中前半部分的基礎知識點
- 瞭解一些統計學的知識也有所幫助,因為最基本的異常檢測是建立在統計學檢驗上的
- 學習時間序列分析也大有幫助,很多工業界模型都無法逃離“時間軸”
- 如果可能的話,建議系統學習上文提到Outlier Analysis這本教科書
- 進階進行論文閱讀的話,大部分研究都發表在資料探勘會議上,主要包括KDD,ICDM,SIAM Data Mining,傳統的機器學習會議不多
根據評論區朋友的補充,提供一些其他參考資料:
從入門瞭解的角度,也歡迎大家參考我的知乎文章:
4. 總結
個人認為,異常檢測在工業應用上大有可為,是為數不多的有良好應用場景且人才缺口較大的領域。同時,因為大家對於網際網路科技公司的嚮往,短時間內人才缺口很難被科班生補上,跨專業的朋友也有得天獨厚的優勢。
但值得注意的是,作為一個小領域,甚至是一個沒那麼火的領域,相關的資料不多,且不成體系。而且資料往往是英文,需要很強的自學能力。不難想象,自學難度以及學習曲線都非常陡峭。
開玩笑的說,富貴險中求,對於技術發展要有我們自己的判斷。在全民深度學習的時代,不妨瞭解一下這些“遺珠”,說不定它會成為你未來很多年的依身傍命之技。